Amazon OpenSearch Backup and Restore: Strategies and Considerations
Amazon OpenSearch is a powerful, scalable search and analytics service offered by AWS. As organizations increasingly rely on OpenSearch for critical data operations, implementing robust backup and restore strategies becomes paramount. This article provides a comprehensive guide to OpenSearch backup and restore, helping AWS practitioners make informed decisions about data protection and disaster recovery.
Key Concepts:
- RTO (Recovery Time Objective): The maximum amount of time allowed for recovery after a data loss event.
- RPO (Recovery Point Objective): The maximum amount of data that can be lost during a data loss event.
- Snapshot: A point-in-time copy of an OpenSearch indices.
Understanding OpenSearch in Your Data Architecture

Before diving into backup strategies, it’s important to understand OpenSearch’s role in your data architecture:
- Search Interface: OpenSearch often acts as a fast search and retrieval interface, with data coming from a primary source that allows for quick index recreation if needed.
- Log Management: In scenarios like logging systems, the persistence of data may be less critical, as OpenSearch may only need to retain data for a limited period. Automatic snapshots taken every hour can suffice here.
- Primary Data Store: In cases where OpenSearch serves as the main data store, such as with vector searches, rebuilding indices may be time-consuming if automatic snapshots do not meet the Recovery Time Objective (RTO) or Recovery Point Objective (RPO).
- High-critical search or logging application: For high-critical availability, consider using a two-cluster setup and cross cluster replication, enabling failover to a secondary cluster if needed.
- Vector Search: OpenSearch’s vector search capabilities are increasingly important for AI and machine learning applications. When used for vector search, OpenSearch often serves as the primary data store for these high-dimensional vectors, making robust backup strategies crucial.
Understanding these roles will guide you in selecting the most appropriate backup and restore strategy for your OpenSearch deployment.
Backup and Restore Strategies
1. Rebuilding Indices from Source Data
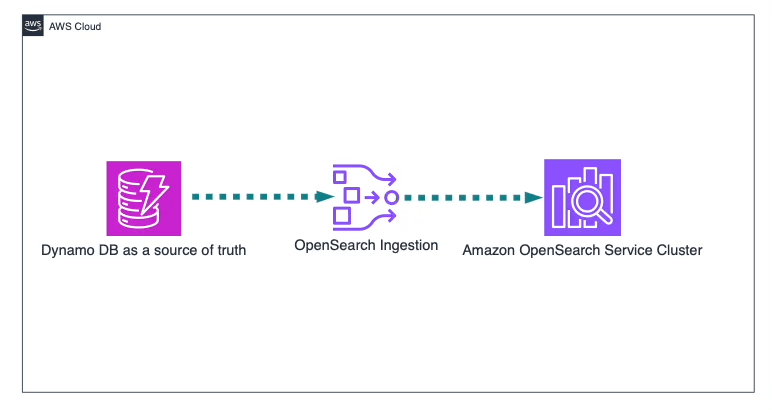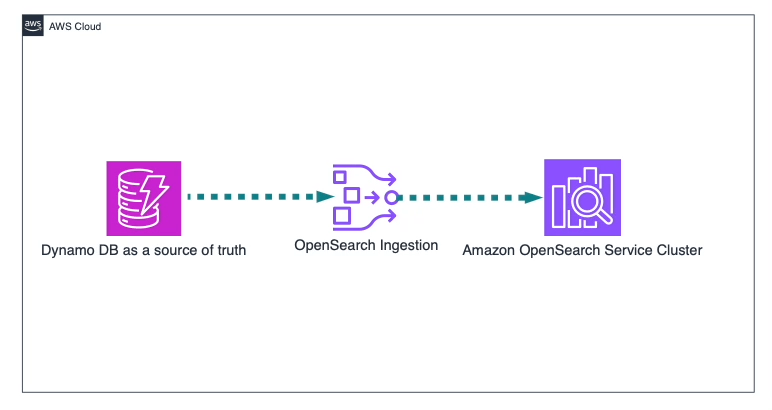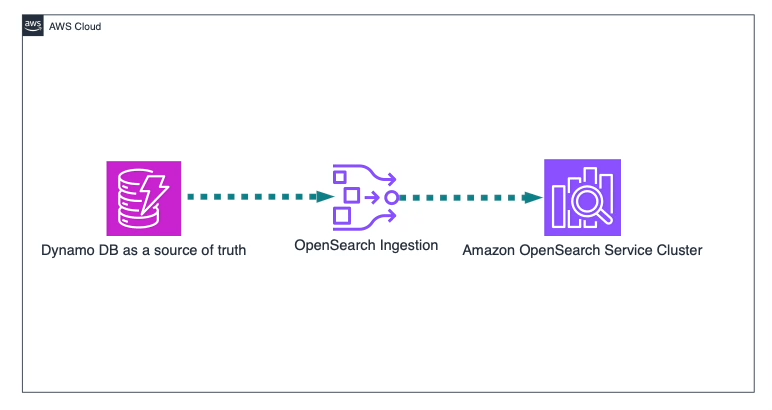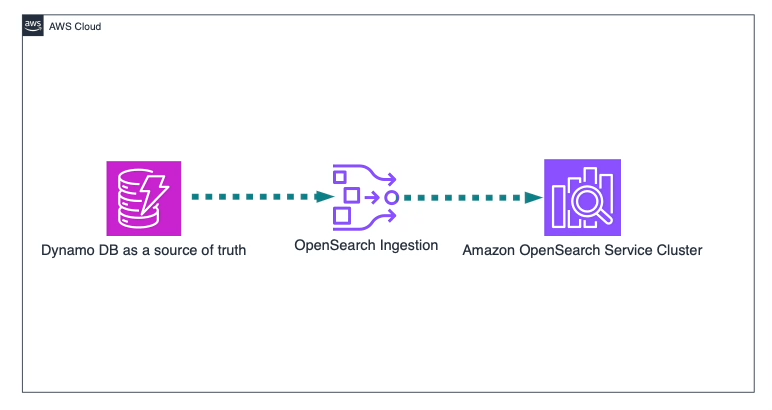
This method involves regenerating your OpenSearch indices by pulling data directly from the primary data store or source system, ensuring the most up-to-date and consistent dataset.
Pros:
- Ensures data consistency with the primary source
- Can be automated as part of a larger data pipeline
Cons:
- Time-consuming for large datasets
- Resource-intensive, potentially impacting performance
- Not suitable for vector search indices due to high computational requirements
Best for: Scenarios where OpenSearch is not the primary data store and rebuild times align with your RTO.
2. Built-in Automatic Snapshotting
Amazon OpenSearch Service offers built-in automatic snapshots that store data in a hidden S3 bucket, providing a safety net against unexpected data loss or cluster failures. These snapshots are taken hourly, with up to 336 retained for 14 days. As incremental snapshots, they minimize disruption and reduce performance impact on the cluster. This frequent schedule ensures a recent recovery point, enabling quicker restoration in case of domain issues.
Pros:
- Automatically configured when the managed cluster is created, requiring no manual setup
- Automation reduces the risk of human error, ensuring consistent backups
Cons:
- Snapshots are stored in a hidden S3 bucket, which is lost if the cluster is deleted
- Limited flexibility in controlling snapshot retention or schedule
Best for: Use cases where an RPO of up to 1 hour is acceptable, and losing the AWS account or the OpenSearch cluster won’t have critical consequences.
3. Manual Snapshots with Custom S3 Bucket
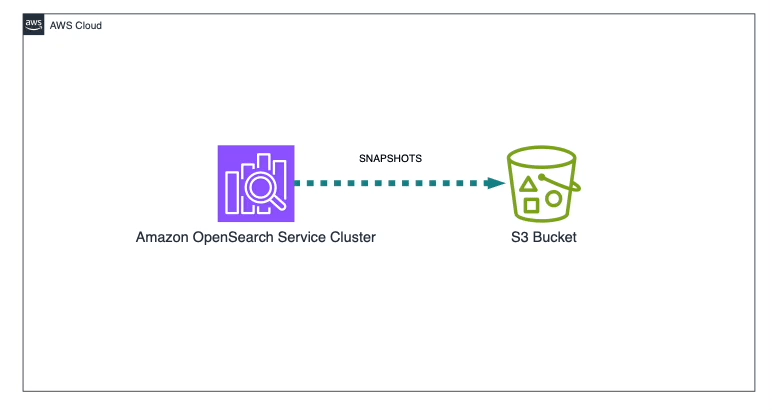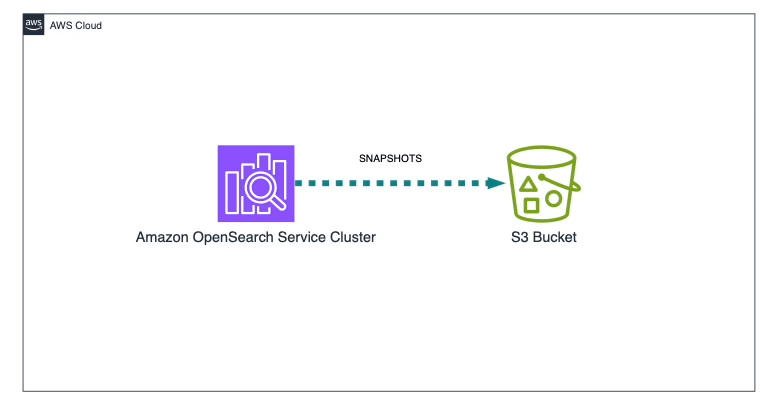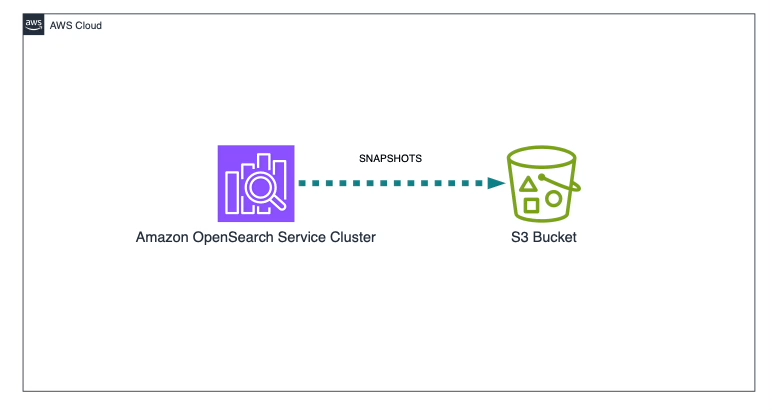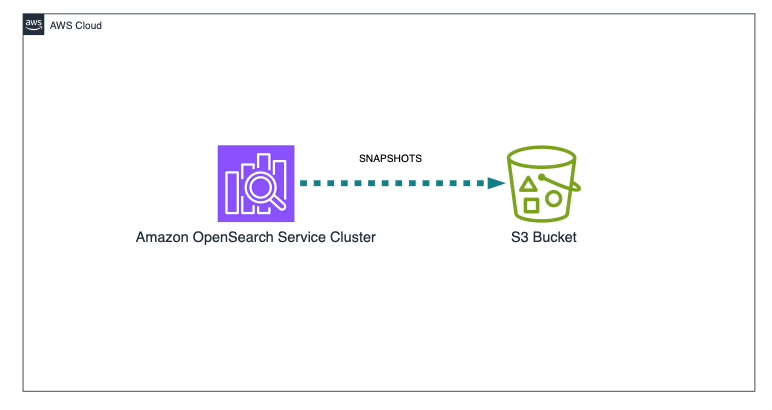
This method enables users to manually create snapshots of their OpenSearch indices and store them in a custom S3 bucket, providing greater control over backup schedules and retention policies. By including this S3 bucket into an AWS Backup plan, users can centralize the management of backups across multiple AWS services. This integration ensures consistent backup policies, streamlines compliance reporting, and allows OpenSearch backups to be managed alongside other essential data backups within the AWS environment.
Pros:
- Snapshots are independent of the cluster lifecycle, persisting even if the cluster is deleted
- Backups can be integrated with AWS Backup for cross-region and cross-account redundancy, enhancing disaster recovery options
- Fine-grained control over retention policies and snapshot timing to meet specific compliance and operational needs
Cons:
- Internal OpenSearch permissions prevent access to certain system indices used for cluster management (typically starting with an underscore “_”). It’s crucial to carefully manage which indices are included or excluded in snapshots, especially during restoration.
- Packages or plugins may complicate restores: If your environment relies on custom packages or plugins, restoring certain indices can be problematic. Index mappings may become corrupt if plugin-related IDs are auto-generated during service setup, making full restoration impossible. In such cases, rebuilding the index may be the only viable solution.
Best for: Production environments with strict data retention, compliance mandates, and advanced disaster recovery requirements.
Note: Disabling automatic snapshots can reduce cluster load. Currently, this can only be done by opening a support ticket with AWS Support.
4. Cross-Cluster Replication (CCR)
This strategy involves using OpenSearch’s built-in cross-cluster replication feature to mirror indices between two or more clusters. This approach ensures that critical data is copied to a secondary cluster in near real-time, providing redundancy in case of cluster failures.
Pros:
- Near Real-Time Replication: Minimizes data loss by keeping replicated indices updated across clusters.
- Supports Complex Workloads: Ideal for cases where indices are frequently updated and rapid data availability is necessary across multiple clusters.
- Lower Recovery Time: Since the secondary cluster already holds a mirrored version of the data, failover and recovery times are significantly reduced.
- Flexible RPO: CCR can be combined with automatic or manual snapshots to achieve optimal RPO, balancing real-time replication with scheduled backups.
Cons:
- Resource Intensive: Requires additional resources to maintain replicated indices, which can increase operational costs. You pay standard AWS data transfer charges for the data transferred between domains too.
- Lag in Replication: Depending on network latency and load, there may be minor delays in data replication, though typically small enough to meet RPO requirements.
Best for: Environments requiring cross-region redundancy with near real-time data synchronization and failover capabilities.
Considerations for Serverless OpenSearch
When using OpenSearch Serverless, it’s important to be aware of key differences and limitations compared to provisioned OpenSearch clusters:
1. Snapshot Management
- No Manual Snapshots: Unlike provisioned OpenSearch domains, OpenSearch Serverless collections do not allow users to manually take or restore snapshots.
- Automatic Backups: Data in OpenSearch Serverless collections is automatically backed up to service-managed Amazon S3 buckets. This backup is managed by the service for disaster recovery purposes, but there is no user-facing control or visibility over these backups.
- Limited Customization: Since manual snapshots and restores aren’t supported, users can’t configure custom backup schedules, retention policies, or use snapshots for migrations.
2. Active Replicas for High Availability
- Redundancy: OpenSearch Serverless maintains at least two active replicas of each shard, distributing them across different Availability Zones to ensure high availability and fault tolerance.
- Automatic Scaling: The platform dynamically scales the number of active replicas in response to increased query load, allowing for fast search performance during peak demand.
- Cost Efficiency: This approach focuses on scaling only the shards under high load, helping to control costs by avoiding unnecessary replication when it’s not needed.
3. Disaster Recovery
- Automatic Failover: The service’s built-in redundancy with active replicas across multiple Availability Zones ensures high resilience. In the event of an Availability Zone failure, traffic automatically fails over to healthy replicas.
- Service-Managed Backups: For disaster recovery, the service-managed S3 backups allow restoration in case of severe issues, though users don’t have direct control over this process.
4. Cost Management
- Cost-Effective Scaling: Since OpenSearch Serverless scales replicas based on query load, it provides a more efficient use of resources, automatically adjusting to balance performance and cost.
- No Infrastructure Management: With OpenSearch Serverless, there is no need to manage infrastructure or worry about underlying server provisioning, making it a low-maintenance option for workloads with variable demand.
Best Use Cases for OpenSearch Serverless
- Non-Critical Search Workloads: OpenSearch Serverless is ideal for environments where the search index can be easily recreated from a primary source of truth, such as a relational database or data lake. Since there’s no manual snapshot or restore option, it’s better suited for scenarios where data loss isn’t mission-critical.
- Dynamic Query Loads: For applications with variable query rates, OpenSearch Serverless excels due to its automatic scaling of replicas based on demand. It can handle fluctuating workloads without requiring manual intervention, making it perfect for search and analytics tasks that see spikes in usage.
- Low Operational Overhead: Organizations looking for a simplified search solution without the need for manual infrastructure management will benefit from OpenSearch Serverless. Its fully managed nature reduces the complexity of setup and ongoing maintenance, making it a good fit for development, staging, or test environments where high availability isn’t the top priority.
Choosing Between Serverless and Managed OpenSearch:
When deciding between OpenSearch Serverless and Managed clusters, consider:
- Workload Predictability: Choose Managed for steady, predictable workloads. Opt for Serverless if your workloads are variable or unpredictable.
- Operational Overhead: Serverless reduces management complexity, making it ideal for teams with limited OpenSearch expertise.
- Customization Needs: If you require fine-grained control over cluster configuration or need specific plugins, Managed may be a better fit.
- Backup and Recovery: If you need manual snapshot capabilities or have strict RTO/RPO requirements, Managed offers more control.
- Cost Structure: Serverless can be more cost-effective for variable workloads, while Managed may be more economical for consistent, high-volume usage.
Monitoring, alerting, testing
Developing a Comprehensive Monitoring and Testing Strategy:
- Set up CloudWatch alarms: Configure alarms for failed snapshot attempts, cluster health status changes, and high CPU or memory usage.
- Implement regular restore tests: Schedule monthly or quarterly restore tests to validate backup integrity and familiarize your team with the restore process.
- Document procedures: Maintain detailed, up-to-date documentation of your backup and restore procedures, including step-by-step guides for different scenarios.
- Conduct failure simulations: Regularly simulate various failure scenarios (e.g., AZ failure, data corruption) to test your recovery processes.
- Monitor replication lag: For CCR setups, track and alert on replication lag to ensure your secondary cluster remains up-to-date.
- Automate where possible: Use AWS Lambda or other automation tools to perform regular health checks and initiate backups or restores when needed.
- Review and update: Conduct quarterly reviews of your backup strategy to ensure it still meets your evolving business needs and compliance requirements.
Comparison of Backup Strategies
| Strategy | Pros | Cons | Best For | Frequency | Storage | Additional Notes |
|---|---|---|---|---|---|---|
| Rebuilding Indices | Ensures data consistency, Can be automated | Time-consuming, Resource-intensive | Small datasets, Non-primary data store | As needed | N/A | Can be time consuming. |
| Automatic Snapshotting | Easy setup, Automated, Reduces human error | Limited retention control, Hidden S3 bucket, Cluster-bound | Development environments, RPO up to 1 hour | Hourly, not configurable | Hidden S3 bucket | Minimal overhead, potential data loss if the cluster is deleted. |
| Manual Snapshots | Persistent after cluster deletion, Flexible retention policies | More setup required, Complexity with OpenSearch permissions | Production, Compliance-heavy environments, Disaster recovery | Customizable | Custom S3 bucket | Can be integrated with AWS Backup. |
| Cross-Cluster Replication (CCR) | Near real-time data replication, Faster failover | Resource-intensive, small lag in replication | Mission-critical workloads, Cross-region redundancy | Real-time replication | Across multiple clusters | CCR can be combined with automatic or manual snapshots. |
Conclusion
Choosing the right backup and restore strategy for Amazon OpenSearch depends on your specific use case, RTO/RPO requirements, and compliance needs. By understanding the pros and cons of each approach and implementing best practices for monitoring and testing, you can ensure the resilience and reliability of your OpenSearch deployment.
Remember to regularly review and update your backup strategy as your data needs evolve. For personalized guidance, consider consulting with AWS support or a certified AWS partner.
Additional Resources
- Amazon OpenSearch Service Developer Guide
- AWS OpenSearch Serverless documentation
- Cross-cluster replication for Amazon OpenSearch Service
- Ensure availability of your data using cross-cluster replication with Amazon OpenSearch Service
- Creating Recommended Alarms for Amazon OpenSearch Service with Terraform