Speed up your Multi-Channel GenAI Solution - Tips from real projects
Your agentic multi-channel, multi-modal GenAI solution idea may be buzz-word-compatible. But to do some expectation management: It will not run as fast as this dog. So, we share some of the tips from our projects on how to speed up your GenAI solution.
Create an automated Test framework
As you will change many parameters on your way to a production-ready solution, you should have a test framework in place that allows you to test your changes reproducibly. This will help you identify the impact of your changes and ensure that you do not introduce regressions. Some people like to play around in a Jupiter notebook and _think _ they have come up with the best solution. But you have to know which changes led to which results. We have seen in projects that sometimes small changes, e.g. in prompts, led to huge differences.
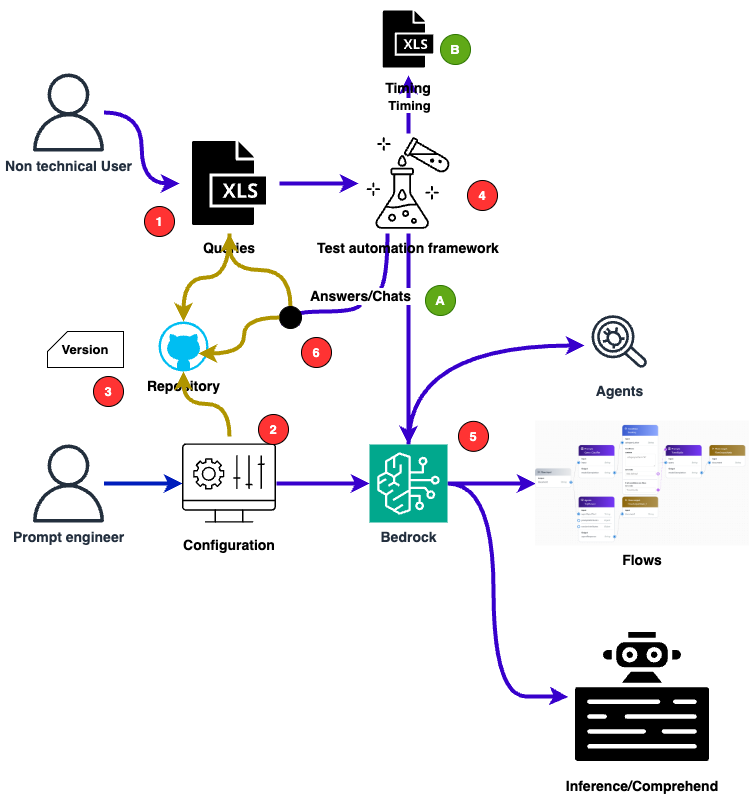
To include business, Prompt-Engineers and developers alike while getting data-driven insights, this is an example of the test cycle we use:
-
Queries or example chats are written in user-friendly Excel sheets This way, no one has to deal with CSV or even code.
-
The configuration, which means all prompts, temperature, model ID and other parameters, are stored in a configuration file. So, it is reproducible and can be versioned.
-
For each test run 1) and 2) are stored in a repository and get a tagged version ID in the repository.
-
The test is run .
-
The automation framework calls Bedrock, the agents the flows or direct comprehend APIS.
-
The results are stored with a reference to the version ID.
Your results are now: A) All chat history or just answers B) The timing of this very configuration
In following this process, you can easily compare different configurations and results
Know thy channel
The main communication channels used are:
-
Synchronous: Voice - yes, piking up the phone is still a thing
-
Semi-synchronous: Chat in any way. Can be a chat widget on your company website, WhatsApp, Facebook…
-
Asynchronous: Email, Fax, Letter As not all customers are as tech-friendly as the reader of this post, snail mail and fax are still a thing.
The timing criticality of the channels is different.
Voice timing criticality
Imagine you talk to someone behind a wall, ask a question and wait for an answer. How long will you tolerate the silence?
You can’t compare it to a normal face-to-face conversation, because you get no visual hints of “I am still thinking”.
The critical delay point here is about 3 seconds. So this is the time your GenAI solution has to answer a question.
Chat timing criticality
Here you have some more time to wait for an answer. You can wait for up to 10 seconds if it is an interactive chat.
If it’s clear to the customer that it is a long-running process, you can wait longer. That depends on the type of customer.
Mail timing criticality
Just take your time.
Choose Model
That’s an easy one. And also a hard one.
The more complex your GenAI task is, the more capable the model has to be.
For instance, embeddings can also be created in German with Amazon Titan, which is fast. But to answer complex questions, you have to use a model capable of those tasks, like Claude sonnet.
This is why the test framework is vital to have. Change models and see the impact.
Use a progress bar
It’s not about the real-time delay but about the perceived time delay. An “I am thinking” bubble on a chat buys you a few seconds. Be cautious with real progress bars if you do not know the exact time it will take. A bar which stays at 90% for a long time is quite annoying.
As for voice, you also can have a voice progress bar. That can be like “we are processing your request.” or just “please wait a few seconds”.
Use cross region inference
See the Bedrock user guide: Increase throughput with cross-region inference. Cross region inference distributes the traffic to different regions.
We have seen a speed-up of 50% in some cases.
Speed up Lambda
To prevent unnecessary local optimisation, at first you have to know where the bottleneck is. If - like in a voice chat - any second counts and you have multiple Lambda functions, cold start really can be a problem.
Python is the most used language in Lambda, but it is not the fastest. So the new “snap start” could be a solution.
Or - translate your python code to GO with the help of Gen-AI. As I have tested here, you can save up to 100ms per lambda call. With asynchrounous calls, you do not have to care about this small amount of time. But with several Lambda and synchronous calls, this can make a difference.
Test agents
Agents are a promising technology to create a more human-like conversation. But they can be slow.
A trace from the AWS Blog Introducing multi-turn conversation with an agent node for Amazon Bedrock Flows (preview) from January 22, 2025 shows that the agent node can be slow.
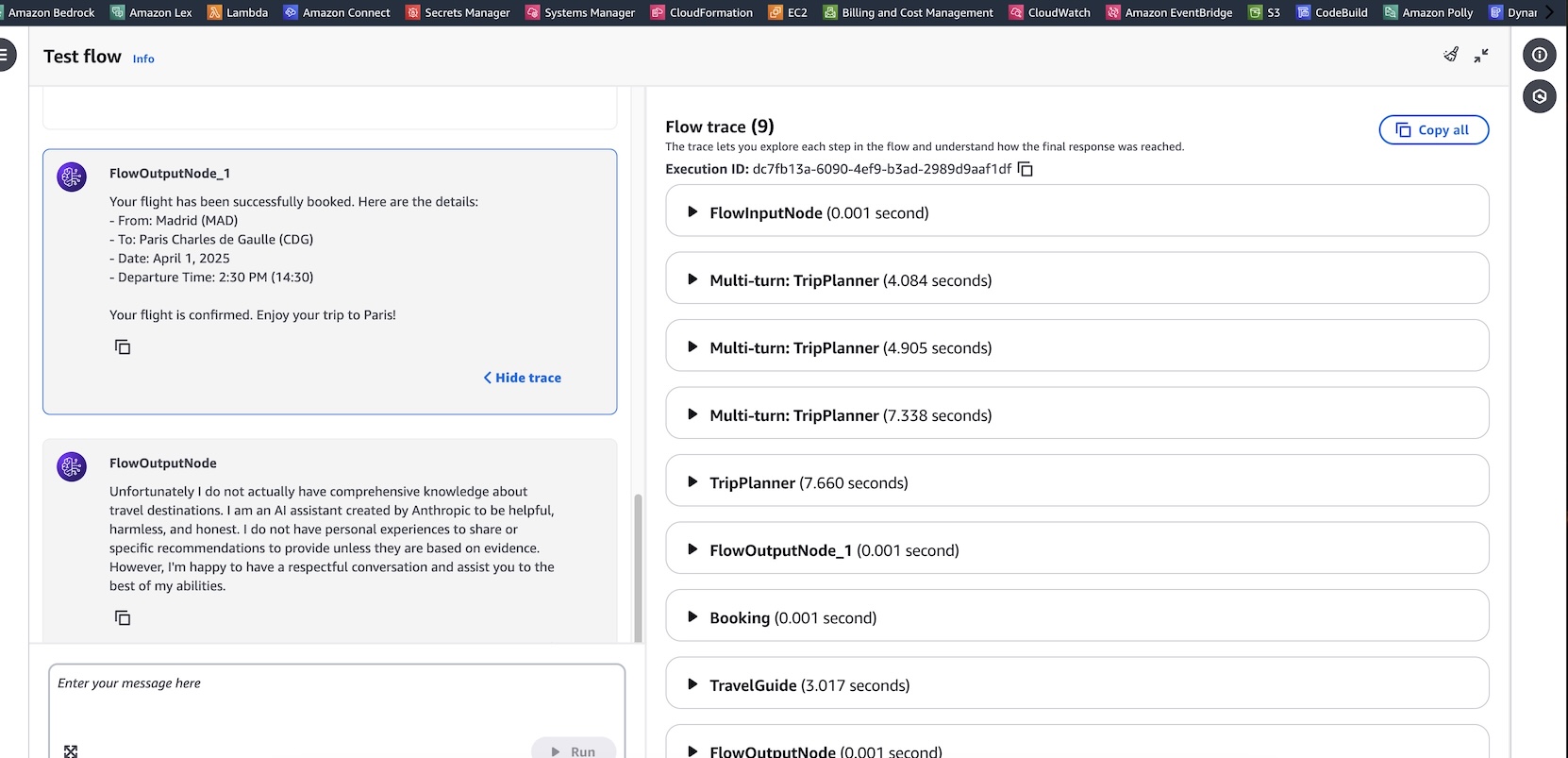 Some of the round trip times are over 7 seconds, which is too long for a voice chat.
Some of the round trip times are over 7 seconds, which is too long for a voice chat.
As you see e.g. in Amazon Bedrock Serverless Prompt Chaining, Bedrock flows are a user friendly way to create agents. But with step functions with a chain of lambda calls, you can speed up the process.
But remember the quote:
Premature optimization is the root of all evil.
So first, solve your solution and then optimize.
Shorten prompts
This is the most vital point. Junior Prompt engineers talk to models like they are humans. But as its an algorithm, you have to be precise and you do not have to be polite. So “Please dear model, I have a problem which i would like to discuss with you” is not the way to go.
Also use models to optimize your prompts. Use bullet points, use xml to seperate data and test (whith the test framework) the difference.
One more tip: You can also change the token length. This can have a huge impact on the speed.
Conclusion
These are just some of the insights we have gained in our projects. Depending on the UseCase there are lots of possibilities to speed up your GenAI solution.
Contact us to develop, optimize, and run GenAI solutions that are fast and reliable! Enjoy building!
See also
Disclosures
This post has partly been supported by GenAI.