From EC2 to C6 - Clear Compliance Chaos with clear Customer Collaboration with MSSP
To battle security compliance is a challenge, which is besten solved as a team sport. We show you some solutions to win this tug of war, like knowing not only the technical, but also the psychological aspects of the game.
This is the way our MSSP works together with you.
The task at hand
This case study evolved from a project, where security compliance was a big issue. A problem what occured was that the effort for maintaining the security compliance was too high. So we analysed not only the process but also the technical aspects and the psychological aspects of the problem. Because with all the security tools we have on AWS, sometimes the problem is a so called “layer 8” problem. Which means, according to the OSI model, the problem is not on the technical layer, but on the human layer.
The customer
The customer is a worldwide leader in technology, focusing on the creation, evaluation, and management of automotive electronics and software-driven systems. Possessing an extensive range of products, they assist car manufacturers, suppliers, and engineering service providers in optimizing the integration of embedded systems. By emphasizing innovation, dependability, and solutions geared towards the future, the client empowers its own customers to adapt to changing industry requirements, achieve compliance, and sustain strong, secure operations.
tecRacer
Since 2011, tecRacer, at the time first AWS partner in Germany, has maintained an unwavering 100% strategic focus on AWS, setting the benchmark for cloud services in the DACH region and Portugal and solidifying its reputation as a leader in the field. tecRacer offers a comprehensive suite of AWS consulting, development, training and managed services, complemented by the innovative contact center solution Amazon Connect. Their seamlessly integrated services combined with in-depth expertise provide complete solutions across the entire cloud lifecycle, from strategy to implementation and operation, delivering an unparalleled, high-performance package to organizations of all sizes and ensuring exceptional customer experiences.
tecRacer Managed Security Service Provider (MSSP)
tecRacer Amazon AWS Managed Services runs your applications in the Amazon Cloud. In doing so, we don’t just “support”, we take over the complete service management for you and thus reduce your costs.
Process Analysis
Big test before going live vs. shift left
Imagine you have a small AWS workload up and running. After deployment (2) you decide to perform a Well Architected Review . You will find out that its a little bit late for this.
Two examples from my review experience:
Fun question - how do you know, how old an AWS account is?
Answer: Just look at the age of the oldest IAM User with static access keys. I have seen keys which were several 1000 Days old. If you are very lucky, nothing has happened. Here comes the problem: You really do not know whether an incident occured or when. If you realize that a kex was leaked, you can only guess, when in the last 1000 days this happened.
See SEC02-BP05 Audit and rotate credentials periodically for details.
Another common example: You decided - for cost reasons - to use only one AWS account for development, testing and production. What could go wrong? See OPS05-BP08 Use multiple environments/Common anti-patterns for some answer.
After some discussion with our AWS architects you are convinced to use several accounts. Just - seperating accounts after the fact is much more difficult than setting up several accounts from the beginning. So you pay double for your cost savings.
The takeaways are:
- You cannot test quality into an existing architecture afterwards, you just detect findings.
- Check quality and compliance as early as possible. This is called “shift left”, as you shift the check left on the timeline
How many is too many?
There are several hundert checks on AWS services. They are bundled in packages like the Well Architected Framework or the CIS Benchmarks. The package you should start with is the AWS Foundational Security Best Practices.
To illustrate some of the security tools, I have deployed this small architecture in a freshly nuked account. Then I scanned the account with three different tools.
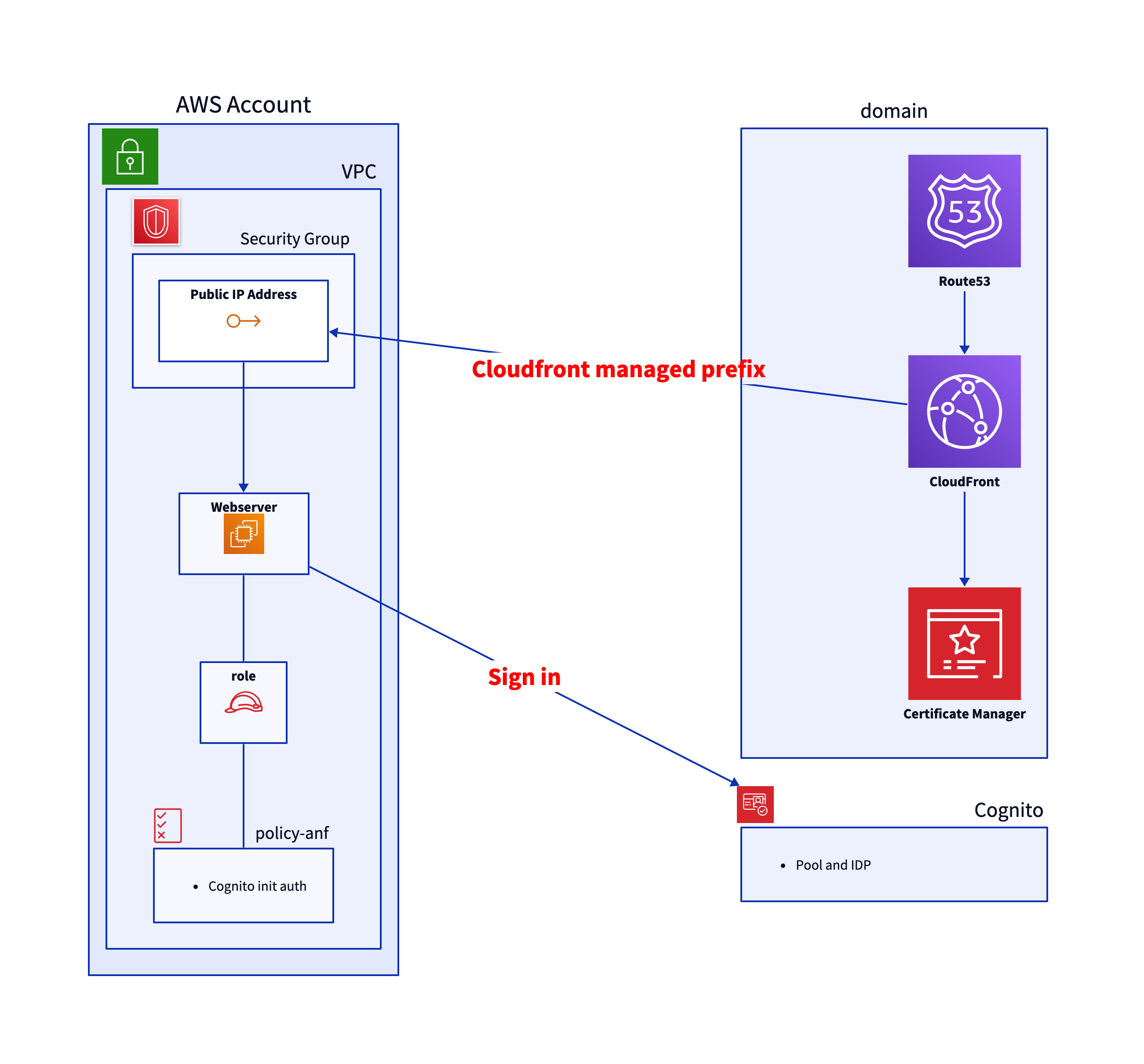
Before reading on, please take a look at the architecture and try to find the security issues. What would you do differently?
A look at tools
I want to show you, that the “score” is just a rough number. Like with all KPI/metris, you should not mix systems. The value is seeing a trend in the numbers, not the number itself.
The tools -which all have different scores - are:
Score Turbot Pipe 19 critical

With Turbot Pipe you can scan a single account in seconds. The score shows just the AWS foundational check. There are mods for other cloud providers availably.
This is a ideal tool to do a quick pre-scan.
Score Security HUB 91%
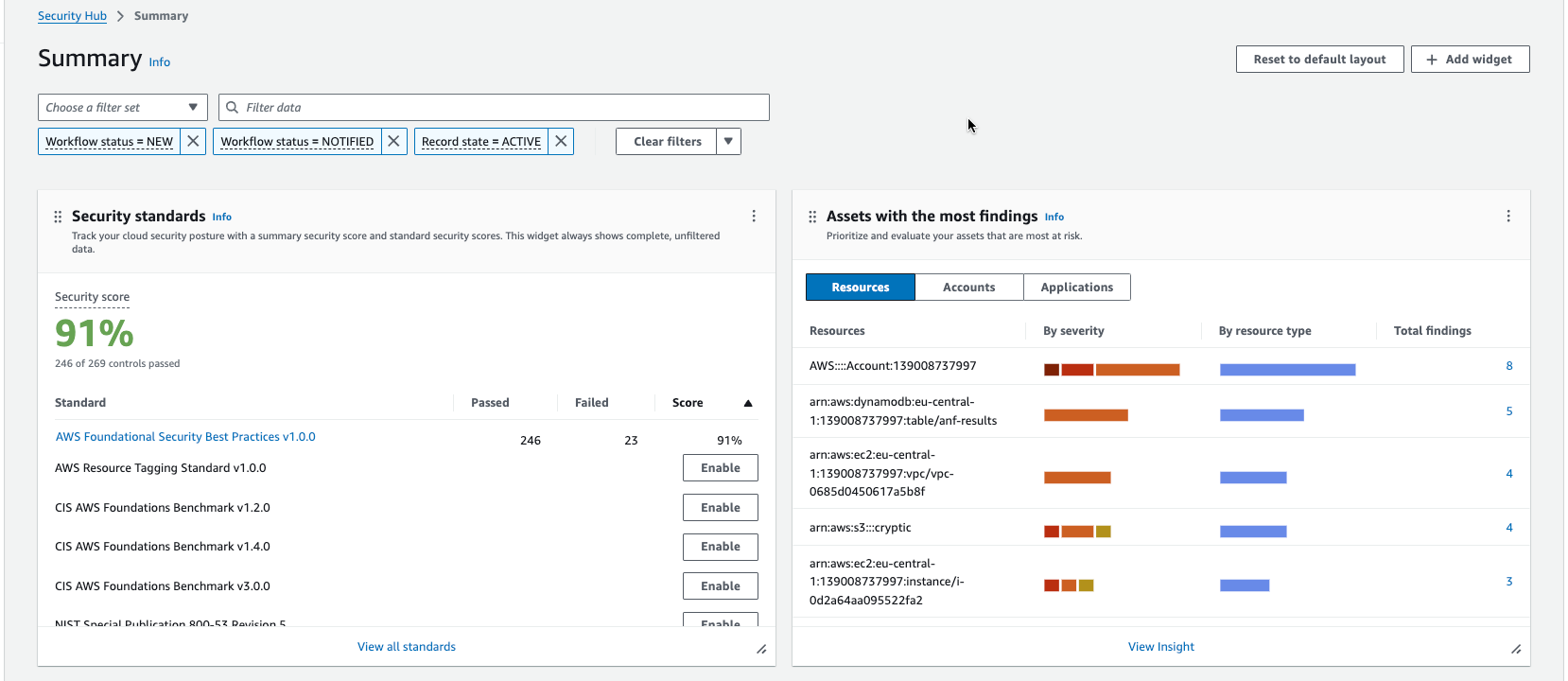
This is on of the AWS batteries included tools. You cannot include other cloud providers or endpoint security (like workstations virus scan)
It needs some time to get started:

If you really know all controls by heart, you can use this tool to get a good overview.
Score Trend Vision One 68%
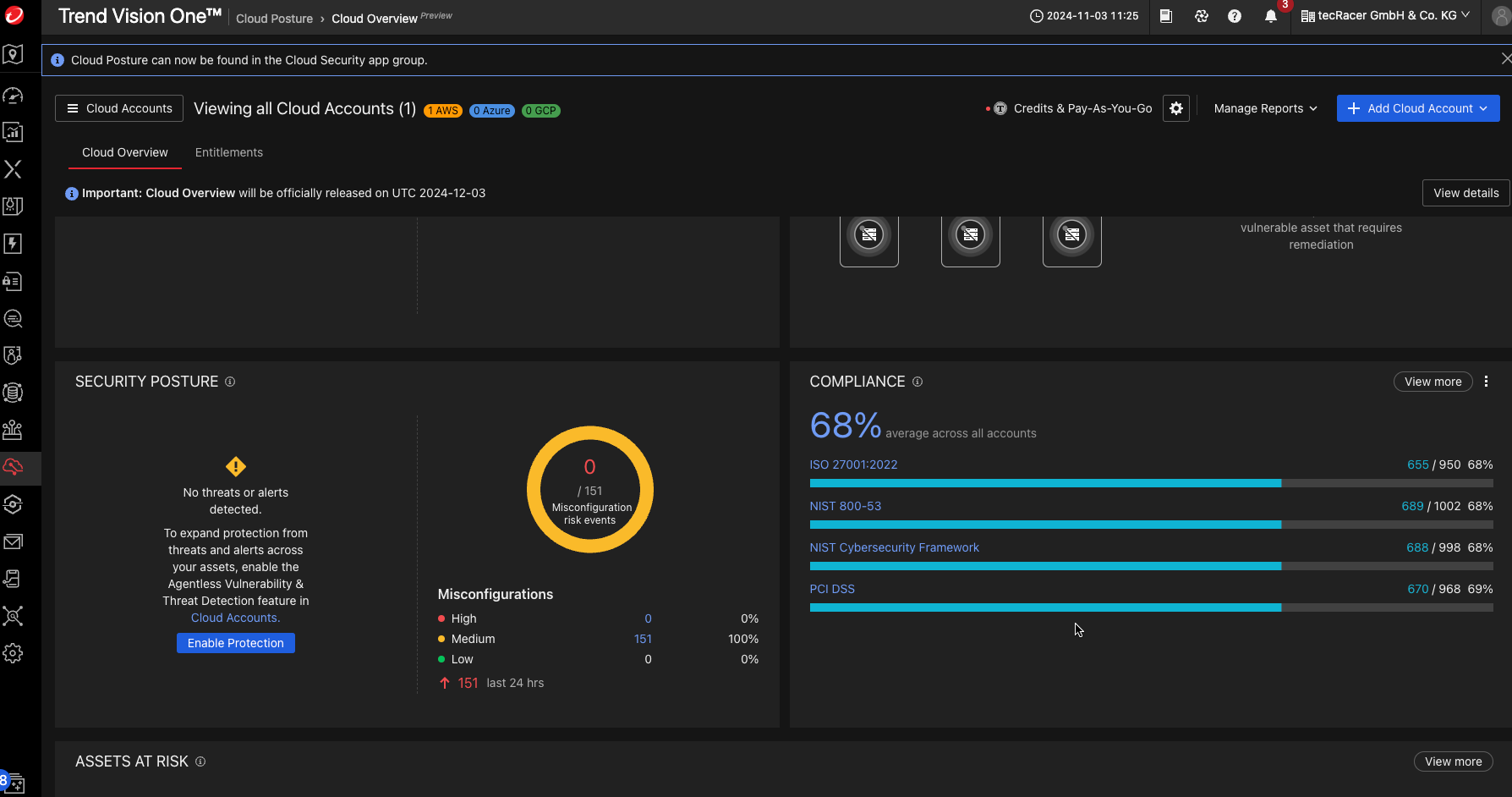
This is the most comprehensive tool. It includes endpoint security and cloud security. It is not limited to AWS. We use it at tecRacer MSSP because the different views on the architecture are bundled in one tool.
Tools and numbers
Which all tools have in common, that the settings for findings like criticality or scope are pre-defined. Let me show you an example, where the prefined settings just not match the usecase.
In the architecture there is a single EC2 instance type t4g.nano. This costs about 4 USD per month.
The findings are:
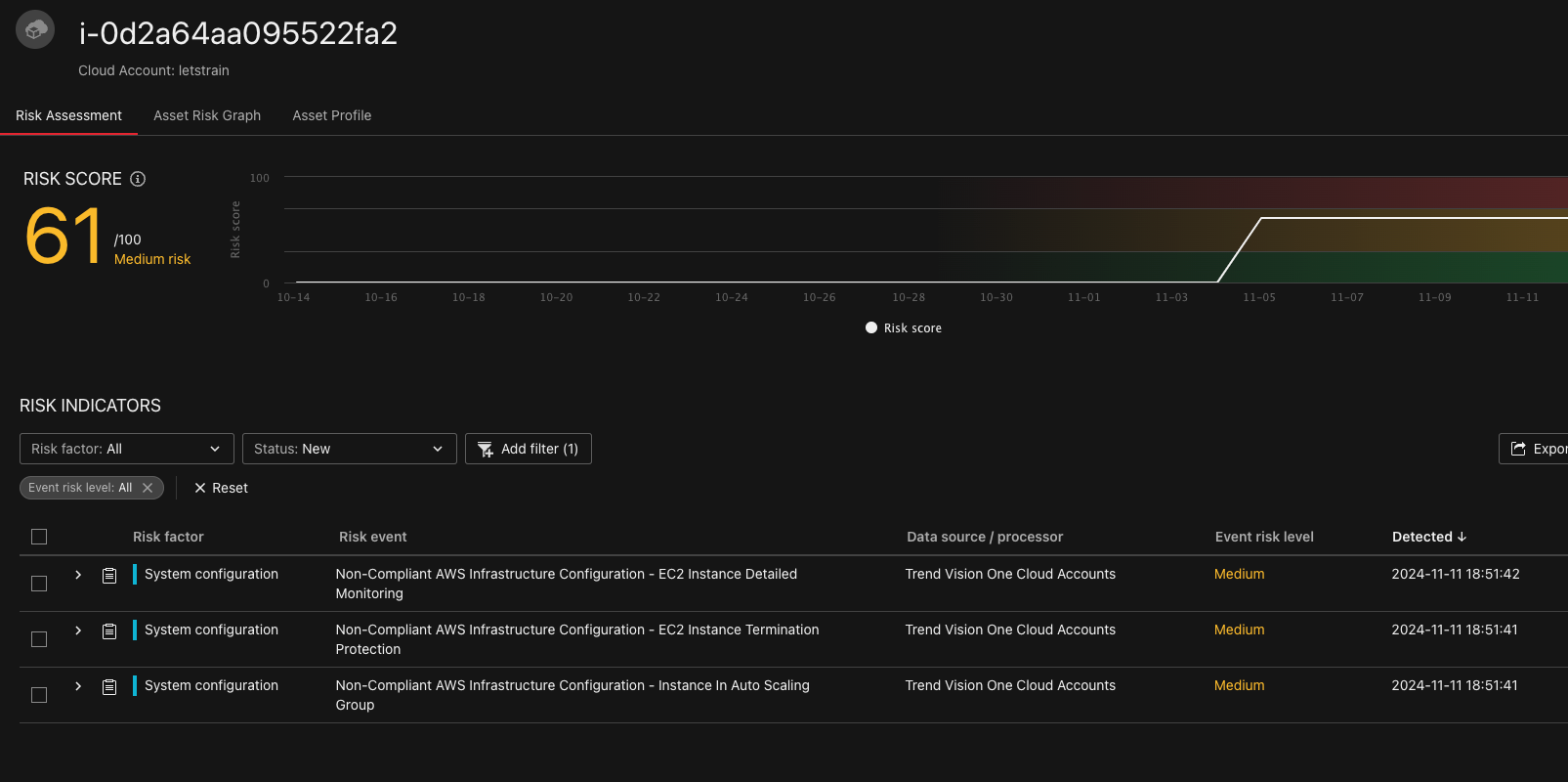
| Finding | Why it does not apply here |
|---|---|
| Instance detailed monitoring is not enabled | This is an rarely used application, so we do not need detailed monitoring |
| Instance Termination protection | This is to be discussed. As the instance is created with Infrastructure as Code, we can recreate it in minutes. |
| Instance in auto scaling group | This is a UseCase for a defined workload with maximum 10 people accessing the application. The server can handle up to 1000 users, so we do not need an auto scaling group. |
Therefore its important to have the ability to adjust the settings to your needs. Like the criticality of a finding, here an example for Trend Vision one:

Another funny example:
To enable Trend Vision one, an Lambda function is created in the monitored account. This lambda has findings from the beginning, which also does not apply:
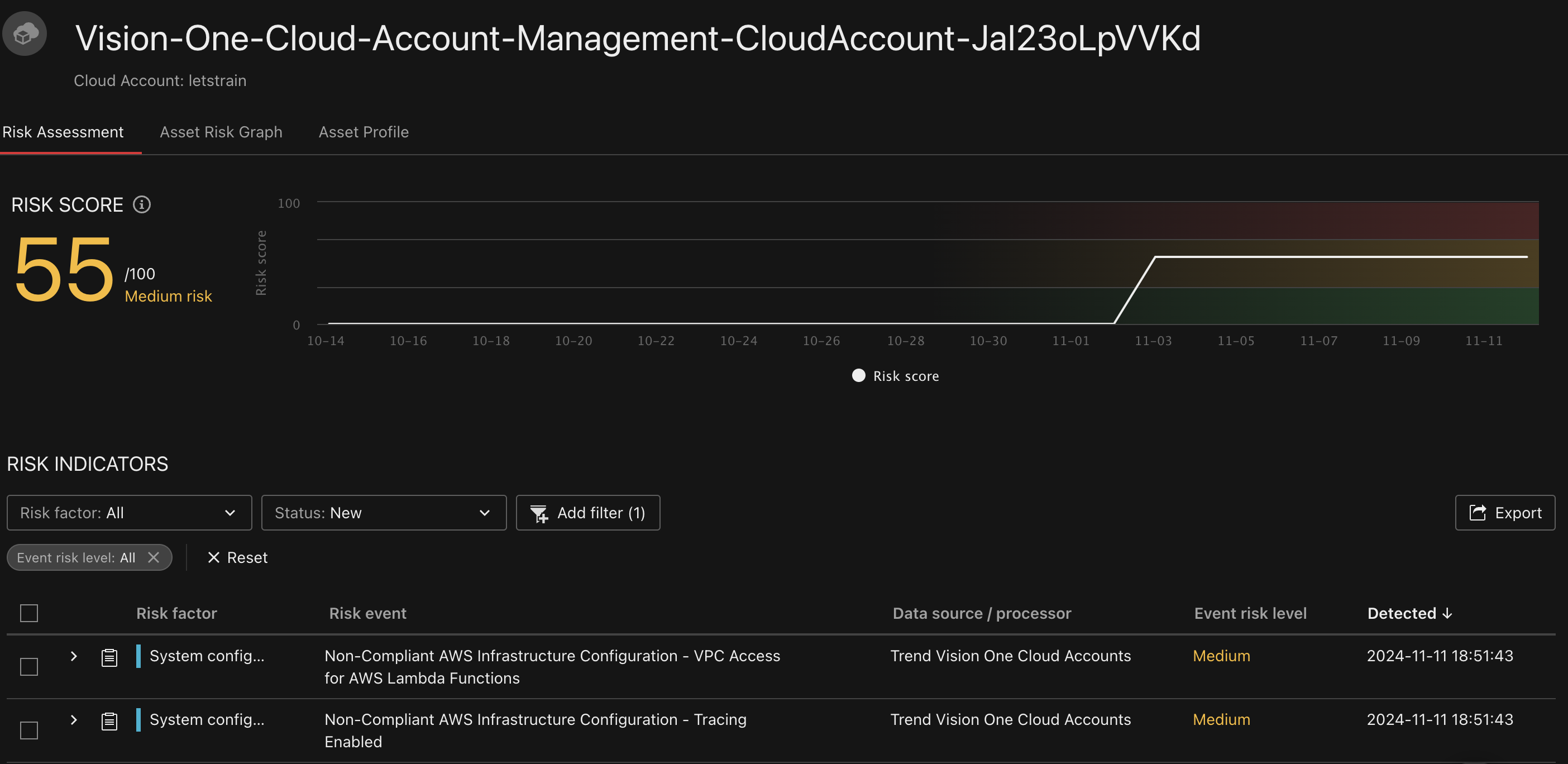
| Finding | Why it does not apply here |
|---|---|
| VPV Access see Lambda.3 | This is not only wrong, it could be harmful |
| Tracing | For distributed services, tracing can be helpful. But it also affects the timing of the lambda. |
This is the Trend Micro information page for the VPC rule, here called Lambda-007:
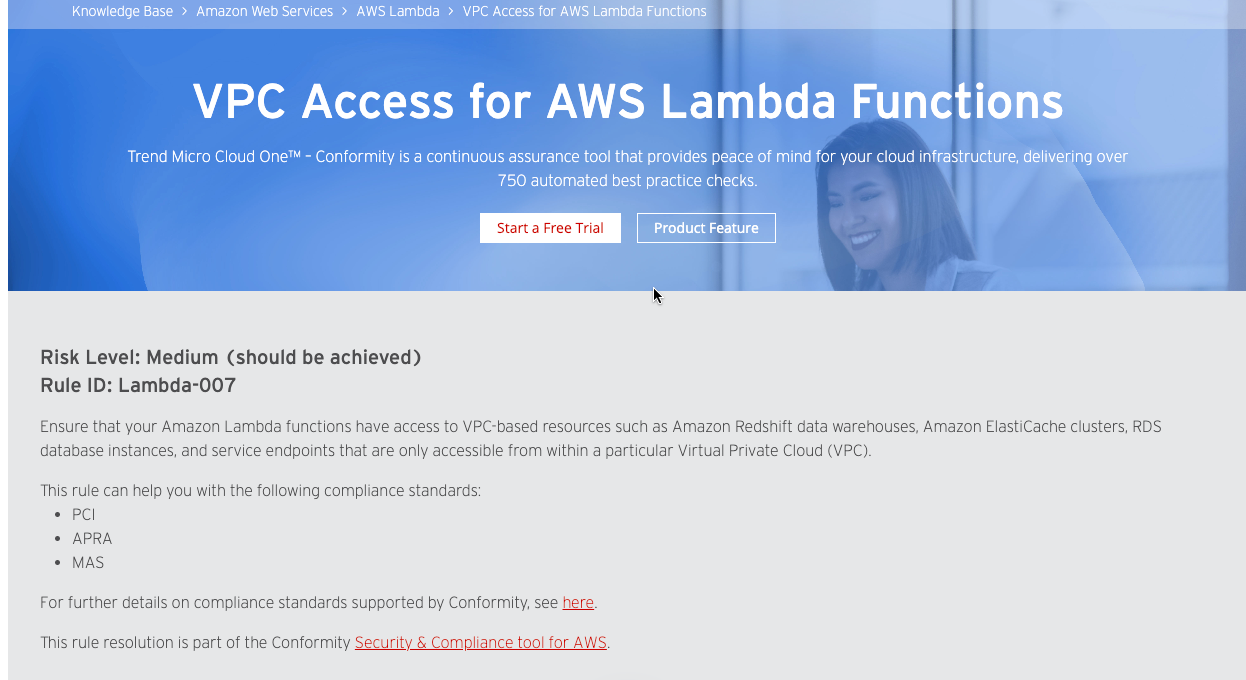
So if and only if the Lambda function have to access resources with private IP you should enable VPC access. But we hade a project where enabling VPC access led to an error which was hard to find:
If you have just on Lambda function on the network card in the VPC and this lambda is just called once a week, then the network card is automatically deleted after a certain ammount of idle time. That means that the first start of the Lambda function after the network card was deleted can take minutes. That caused the lambda to time out and procuced an error.
Not just noise - know thy scope
The two examples showed noise, which should be suppressed by rules. Many other findings pointing to real problems. And thats just what the findings are: The point you to a possible problem. You have to decide if this is a real problem or not.
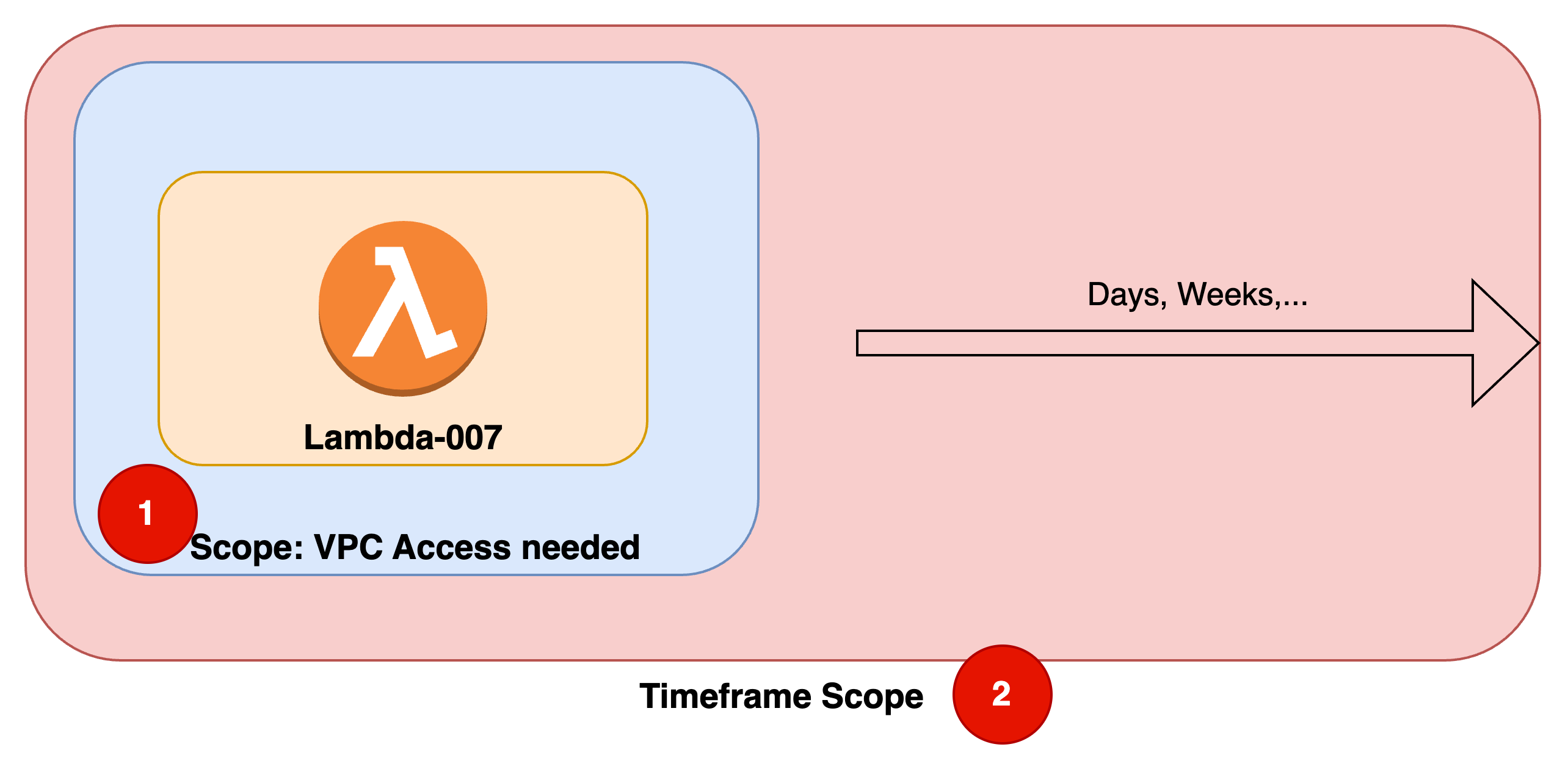
- The first question is: What is the scope of the findings? Does that fit my usecase
- Then enlarge the time frame: Will that become a problem in the future?
Some general questions you might find usefull to enlarge the scope of your thinking:
A) What will happen, if the finding will be remediated?
B) What will not happen, if the finding will not be remediated?
C) What will happen, if the finding will not be remediated?
D) What will not happen, if the finding will not be remediated?
Remediaton means fixing the finding, in the example put the Lambda function in a VPC.
With the Lambda example:
A) a network card is created and will be automatically deleted. All calls from the Lambda function will be coming from a static ip. The very first call will take minutes.
B) Resources with a private IP will not be accessible
C) First cold start will take only milliseconds/seconds
D) Timeout of the Lambda
To make a good decision you have to work with the scope and with some psychological principles.
Psychological bias
Commitment and Consistency
Robert B. Cialdini describes in his book “Influence” the principle of commitment and consistency. If you have invested mental or physical resources in a decision, you are more likely to stick to it. The result is, that you are more likely to stick to a decision, even if it is wrong. That applies to the findings of the security tools as well. You have decided about the architecture, like using only one AWS account and you will defend this decision. Unless you work trustfully together with an independent observer, eg from MSSP.
Social System Culture
I have shown that you need extensive knowledge in AWS operations to make a good decision about the findings of the security tools. When you develop software running on AWS you need extensive knowledge and expierence in software development.
Working trustfully together in the Collaboration Space gives you the ability to overcome the psychological bias .
Solution: The shift left collaboration pattern
To cut through the noise of the many findings, know thy scope and collaborate with an independent observer, here is a very simplified recipe:
- Shift left: Start with the security tools as early as possible. Establish a baseline with ideally zero open findings.
- Collaboration Space: Work trustfully together with an independent observer from MSSP. This person should have a good understanding of the security tools and the architecture.
- Discuss delta, the news findings after each sprint. This way the ammount of findings is managable
In the discussion between dev and ops:
- Know the scope of the findings
- Enlarge the time frame
- Ask the 4 questions
Results
By broading the scope from “just technical” to “technical and psychological” we have achieved the following results:
- The ammount of findings is managable
- Changes to shift left ind the development and deployment process made is possible to detect potential risk issues early
- The findings are not just noise, but point to real problems
Conculsion
As technical focused people we tend to focus only on the technical aspects of a problem. But the psychological aspects are as important as the technical aspects.
What’s next?
If you need MSP or MSSP Hosting for your AWS workloads, don’t hesitate to contact us at tecRacer.
Thanks for reading. Enjoy building!