Regaining Amazon QuickSight SPICE capacity
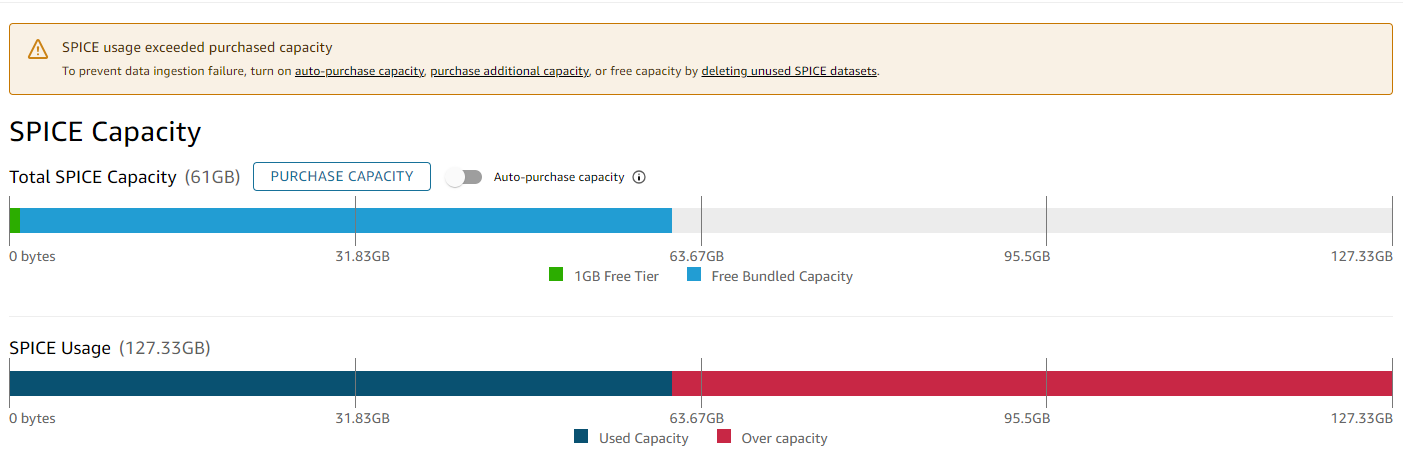
This week, we had a bit of an issue with our Amazon QuickSight account: we ran out of space! Amazon QuickSight is a business intelligence (BI) solution offered by AWS. It is a versionless, serverless, auto-scaling solution with deep integration with AWS services and can be interacted with using the AWS SDK, the AWS CLI, or the QuickSight Console.
While Amazon QuickSight supports auto-scaling for storage (or more precisely, the automatic purchase of storage capacity when needed), we didn’t enable it for our Amazon QuickSight account. A few days ago, when experimenting with numerous datasets, we ended up using all of our purchased storage capacity.
When using Amazon QuickSight, you can either store your data in SPICE (Super-fast, Parallel, In-memory Calculation Engine) or directly query it from your data source whenever needed. Datasets that are directly queried from your data source do not consume SPICE capacity.
There are some advantages when saving datasets in spice:
- Analytical queries process faster.
- Datasets saved in SPICE can be reused at will without incurring additional costs.
- Analyses and dashboards are not limited to the performance of the data source.
So, we ran out of SPICE capacity. Whe importing a SPICE dataset uses up all of SPICE remaining capacity, the following happens:
- SPICE isn’t able to estimate the size of a dataset before importing it, so the dataset is first imported.
- Even if it’s determined during the import of a dataset that no more SPICE capacity is available, Amazon QuickSight will import the whole dataset into SPICE. Any capacity on top of the Free and the purchased capacity will be referred as over capacity.
- Amazon QuickSight will charge for the actual capacity usage. SPICE capacity currently costs $0.38 per GB per month.
- Further ingestion won’t be possible.
- To be able to refresh datasets or create new SPICE datasets again one will have to either purchase enough SPICE capacity or delete datasets until there is available capacity.
In our case, there was no need to purchase more capacity so we decided to delete datasets. Our Amazon QuickSight account content important datasets and analyses, so we couldn’t just delete datasets at will. We needed to find the exact datasets that were using much more capacity than expected.
When you open a Dataset in Amazon QuickSight, you can see how much SPICE capacity the dataset is using.
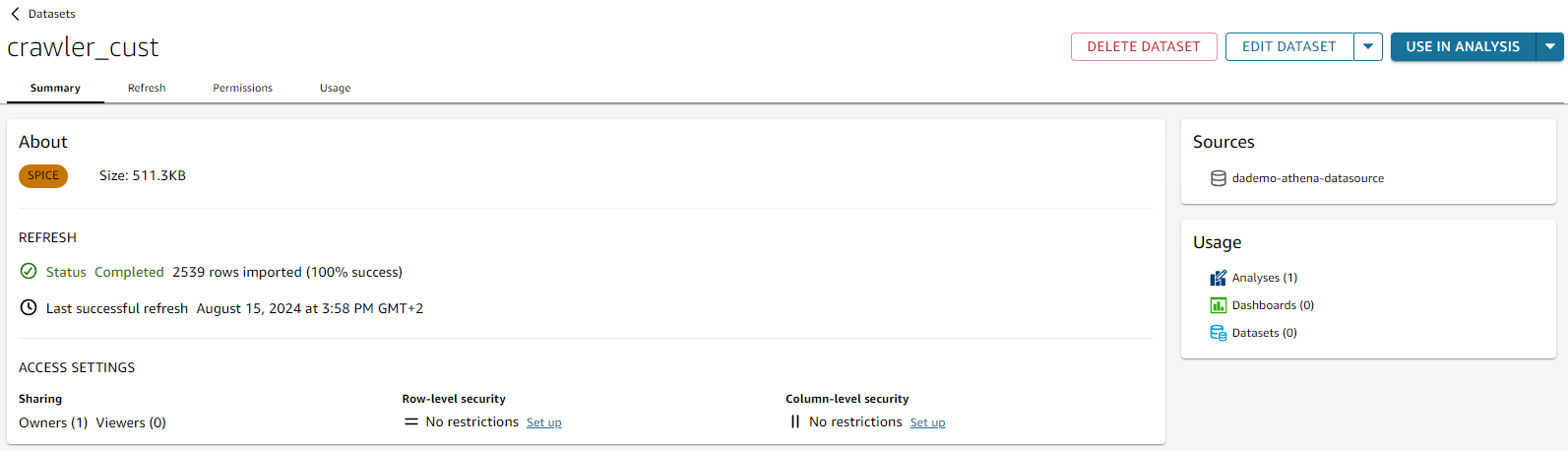
Having more that 100 datasets in our accounts, it would be troublesome to first get access to each of them and then open each and everyone of them to see how much SPICE capacity is used by each dataset.
Here comes the Amazon QuickSight API!
It is possible to interact with Amazon QuickSight using the AWS SDK. This provides us with a way to implement a script that will have a look at each of the datasets and let us know which datasets are the top capacity consumers in our account.
The following Amazon QuickSight APIs are helpful to achieve our goal:
- ListDataSets: List all datasets available in an Amazon Quicksight account within a given region
- DescribeDataSet: Describe a dataset and provide information such as the used SPICE capacity
- DeleteDataSet: Delete a dataset. While it is possible to automatically delete datasets using a lot the available capacity, that is an operation that should be done after careful consideration so an automated deletion of datasets was not implemented in the solution.
The solution is implemented as a Python script that uses the AWS Python SDK (boto3) and requests an account ID to list the top-10 datasets with the highest SPICE capacity usage. The script only considers datasets with a size of 128MB or larger. The following snippet shows the main functions in the script:
def get_top_spice_capacity_datasets(
datasets_size_infos: list[DatasetSizeInfo], top_n: int = 10, minimum_capacity_in_bytes: int = 128 * 1024 * 1024
) -> list[DatasetSizeInfo]:
"""
Returns the top N datasets with the highest consumed Spice capacity, filtered by a minimum capacity.
Args:
datasets_size_infos (list): A list of dataset size information objects.
top_n (int): The number of top datasets to return.
minimum_capacity_in_bytes (int): The minimum capacity in bytes to filter datasets.
Returns:
list: A list of dataset size information objects for the top N datasets.
"""
filtered_datasets_size_infos = [
d for d in datasets_size_infos if d["ConsumedSpiceCapacityInBytes"] >= minimum_capacity_in_bytes
]
sorted_datasets = sorted(
filtered_datasets_size_infos, key=lambda x: x["ConsumedSpiceCapacityInBytes"], reverse=True
)
return sorted_datasets[:top_n]
def list_top_spice_capacity_datasets(
account_id: str, top_n: int = 10, minimum_capacity_in_bytes: int = 128 * 1024 * 1024
) -> list[DatasetSizeInfo]:
"""
Lists the top N QuickSight datasets with the highest consumed Spice capacity.
Only datasets with at least the configured minimum capacity are returned.
Args:
account_id (str): The AWS account ID.
top_n (int): The number of top datasets to return.
minimum_capacity_in_bytes (int): The minimum capacity in bytes to filter datasets.
Returns:
list: A list of dataset size information objects for the top N datasets.
"""
datasets_summaries = list_quicksight_datasets_summaries(account_id=account_id)
dataset_size_infos = get_datasets_size_infos(datasets_summaries, account_id=account_id)
return get_top_spice_capacity_datasets(
dataset_size_infos, top_n=top_n, minimum_capacity_in_bytes=minimum_capacity_in_bytes
)
The full script is available on Github.
Executing the script with our QuickSight account ID generated the following (redacted) output.
> python list_top_spice_capacity_datasets.py
Enter your AWS account ID: 123456789012
Error getting dataset size for 21ed69b7-8ffe-41d4-b6e3-d9e0b8411d13/KDS-S3-Z4891-bc8d-4e6dcf374fb3_reduced.csv: An error occurred (InvalidParameterValueException) when calling the DescribeDataSet operation: The data set type is not supported through API yet
Error getting dataset size for 4b62807e-cda3-4217-b18d-5cb1e6d3e88a/titanic-demo-file: An error occurred (InvalidParameterValueException) when calling the DescribeDataSet operation: The data set type is not supported through API yet
Error getting dataset size for 64cb01af-7def-4d23-bc63-b9e6f0dec636/cust.csv: An error occurred (InvalidParameterValueException) when calling the DescribeDataSet operation: The data set type is not supported through API yet
[{'Arn': 'arn:aws:quicksight:eu-west-1:123456789012:dataset/1ade907f-c5cc-4adc-a592-8469e5a3da9f',
'ConsumedSpiceCapacityInBytes': 135001466281,
'DataSetId': '1ade907f-c5cc-4adc-a592-8469e5a3da9f',
'ImportMode': 'SPICE',
'Name': 'global-electronics-retail'},
{'Arn': 'arn:aws:quicksight:eu-west-1:123456789012:dataset/3acccb06-a1f3-6a5d-a7bd-e1cf963303ee',
'ConsumedSpiceCapacityInBytes': 285941024,
'DataSetId': '3acccb06-a1f3-6a5d-a7bd-e1cf963303ee',
'ImportMode': 'SPICE',
'Name': 'training02 dataset'}]
Datasets created from uploaded files currently do not support the DescribeDataSet API. These are the ones generating the listed errors.
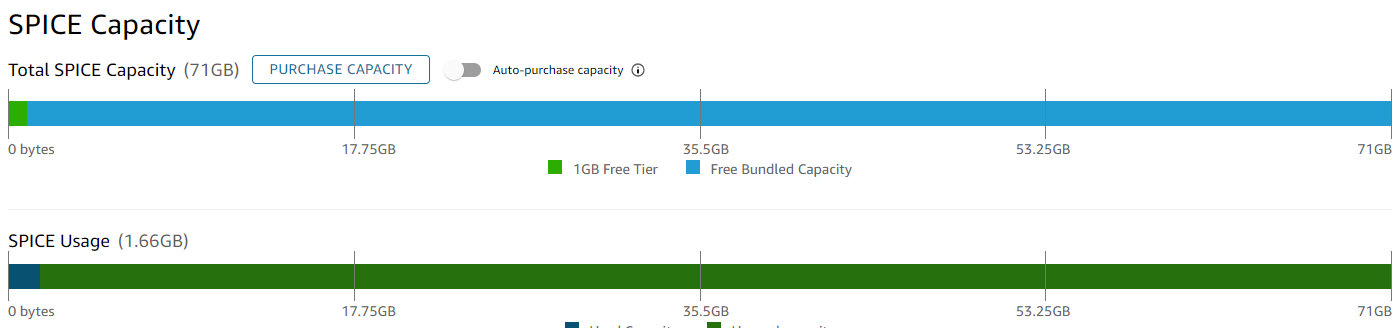
At the end of the console we see which datasets are currently using most of the SPICE capacity in our account. It’s then easier to delete unneeded datasets to the regain the SPICE capacity. As can be seen, a single dataset was responsible of around 99% of the SPICE capacity usage in our account. Deleting it helped us regain our SPICE capacity.
— Franck
Links:
Cover from Wikipedia
{kind=link}