RAG AI-LLM Databases on AWS: do not pay for oversized, go Serverless instead
The RAG - Retrieval Augmented Generation is an approach to reduce hallucination using LLMs (Large Language Models). With RAG you need a storage solution, which is a vector-store in most cases.
When you have the task to build the infrastructure for such a use case, you have to decide which database to use. Sometimes, the best solution is not the biggest one. Then you should go serverless to a smaller solution, which fits the use-case better. In this post, I introduce some of the solutions and aid you in deciding which one to choose.
In a next post, I’ll show you a complete serverless solution that only uses AWS Lambda.
What is semantic search?

We have distributed knowledge in many documents, like the marked regions in these books. We store information snippets in a database. Now, we want to find the information snippets relevant to a question.
Before semantic search, we used text search. So if we search for “good”, we get all snippets that contain the word “good”. So far, so good. But when we type “great”, text search will not find “good” because the characters are not the same. With semantic search, we can find “good” when we search for “great”. The search engine knows that “good” and “great” are synonyms. Or you could say they are semantic neighbors.
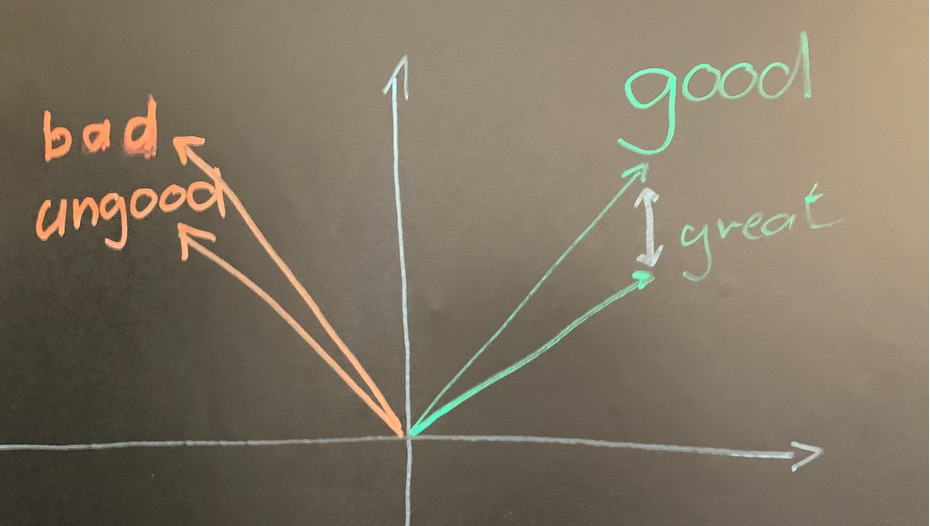
We search for words with the smallest (semantic) distance to the search term. “Good” is near “great” but far away from “bad”. An LMM, e.g. Amazon Titan calculates the vectors for the information snippets or chunks. A code example is bedrockembedding. With such a library, you call singleEmbedding, err := be.FetchEmbedding(content) and get the vector for the content.
Deciding a solution architecture
There are several questions you should answer before choosing a database:
- How big is the data?
- How many records will you have?
- What is the size of the data?
- Which kind of documents will you have to ingest?
- Text
- Office Documents: Word, Excel, Powerpoint -…
- What are scaling requirements?
- Does the service run in your region? As most of our clients are based in Germany, we prefer the Frankfurt region.
- Do you need additional features?
Some T-Shirt size solutions overview
| Size | Database | Cost | Additional Features | Control over search |
|---|---|---|---|---|
| XL | Amazon Kendra | $$$$$ | ⭐⭐⭐⭐ | ⭐⭐ |
| L | Amazon OpenSearch serverless | $$$$ | ⭐⭐⭐ | ⭐⭐⭐ ⭐ |
| L | RDS PostgreSQL pgvector | $$$ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| M | PineCone | $$ | ⭐⭐ | ⭐⭐⭐ |
| S | Local Vectorsearch | $ | ⭐ | ⭐⭐⭐⭐ |
| XS | Embedded VectorSearch | $ | ⭐ | ⭐⭐⭐⭐⭐ |
While the additional features ratings are highly subjective, it should just give you a hint when to choose this solution.
XS - on the way to true Serverless
With some of these solutions, the term “serverless” is misleading.
In the AWS community “Serverless” was meant as:
- Services scales down to zero. So if you do not use it, you don’t pay
- Scaling, configuration, management, and maintenance of underlying servers or containers is hidden from you
See lastweekinaws: No, AWS, Aurora Serverless v2 Is Not Serverless for discussion. Let’s have a closer look at the solutions which have Serverless in the name.
Overview of the standard solutions
Amazon Kendra
Kendras search engine is a language processing (NLP) bases engine. As far as AWs gives information about the internal services, it is not embedding based search. The accuracy of the searches can be as good as embedding, depending on the use case.
Kendra has many connectors, like Web crawl, S3, RDS,.. which makes the setup very easy. Besides text and pdf, Kendra can ingests Microsoft Office file formats Excel, Powerpoint and Word.
The downside of this flexibility is the price. Minimum price per month is $810.
Kendra is not available in Frankfurt, but in Ireland, which is relevant for data inside the EU.
When to use Kendra
You want to ingest different file types from various connectors and don’t want to configure search details. The Kendra model can be optimized with e.g. relevance tuning or feedback on answers. I have shown you a fully running example here: Stop LLM/GenAI hallucination fast: Serverless Kendra RAG with GO
When not to use Kendra
- When you have single file type documents with a low record count (<= approx. 10.000 records).
- When you need eu-central-1 availability.
- When the project is cost-sensitive
Amazon OpenSearch Service Serverless
You can use OpenSearch as an embedding vector store. See AWS Blog - Amazon OpenSearch Service’s vector database capabilities explained.
The OpenSearch pricing needs some calculation, the document says:
- “You will be billed for a minimum of 4 OCUs”
- “2x indexing includes primary and standby, and 2x search includes one replica for HA "
With the Frankfurt pricing (March 31 2024):
| Service feature | price per hour |
|---|---|
| OpenSearch Compute Unit (OCU) - Indexing | $0.339 per OCU per hour |
| OpenSearch Compute Unit (OCU) - Search and Query | $0.339 per OCU per hour |
You get a minimum price of 1.356/$ per hour which will result in a minimum fee of 976/$ per month.
The service is available in Frankfurt.
When to use OpenSearch
- You need the additional features of OpenSearch
- Large scale document size and count
- Previous OpenSearch knowledge exists
- OpenSearch is already in use
- Classic full-text search, BM25, is needed
- You want to use Neural Sparse Retrieval Search.
Thanks to Alexey for a few tipps.
When not to use OpenSearch
- When the project is cost-sensitive
- No Previous OpenSearch knowledge exists
RDS PostgreSQL pgvector
pgvector is an extension for PostgreSQL, which allows you to store and search embeddings. The advantage of this solution is that you can use your existing SQL knowledge.
In this example API for RAG with embedding you get a fully running example with a Go RAG/pgvector model.
You work with a normal RDS PostgreSQL database:
Insert a vector:
insert into items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');
Read a vector:
rows, err := conn.Query(ctx, "SELECT id, content,context FROM documents ORDER BY embedding <=> $1 LIMIT 10", pgvector.NewVector(embedding))
The operator <=> is the cosine similarity operator, which selects the most similar vectors.
For small projects, you may start with a small db.m3.medium instance which would cost around 180$ with 100% utilization and 30GB. See calculator.
When to use pgvector
- You want to use your existing SQL knowledge
- Your usecase includes additional Data
When not to use pgvector
- You need a very high performance vector database like PineCone As its easy with AWS to spin up an infrastructure I would suggest doing an proof of concept with a load test to really see the performance of the solution.
- You want a true Serverless solution
Pinecone
There are several other vector databases as non AWS solutions, Pinecone is just one of them. An APN Blog Post from 21 MAR 2024, with the headline Reimagining Vector Databases for the Generative AI Era with Pinecone Serverless on AWS implied that PineCone is an AWS service. But - its a vector database for AWS, not an AWS Service.
The pricing is nearly serverless and it looks like a good alternative to consider.
See
- https://www.pinecone.io/pricing/#calculator
- https://aws.amazon.com/blogs/apn/reimagining-vector-databases-for-the-generative-ai-era-with-pinecone-serverless-on-aws/
Pinecone is not available in Frankfurt.
When to use PineCone
- You just need a high performance vector database
- Large scale document size and count
When not to use PineCone
- You only want to use AWS based services, no third party
True Serverless Solutions
Now we go for solutions which fits better for smaller projects :

If the database itself is also running on the Lambda microvm, you only pay when you use it. This is “true” capital S Serverless.
There are several vector-database solutions for Python, Node an GO available.
The first distinction is whether you run the database as a server or directly in use a library to work with the database files. The server bases solution have a little bit more overhead. With the server database you have to make sure that the database is capable of running with Lambda cold-starts and warm-starts. Some solutions will not be runnable on Lambda because of security constraints.
The second decision is whether you import data into the database while the Lambda function runs or you import the data before the Lambda function runs.
If you have a fixed dataset, using pre-imported data is much faster for the execution of the querys itself.
Local Vectorsearch
With local vectorsearch I mean running a vectordatabase server and a client separately on a function.
When to use local vectorsearch
- Small amounts of data
- price sensitive
- Import data inside the Lambda function
When not to use local vectorsearch
- Additional features needed
- Large scale document size and count
Embedded VectorSearch
With embedded search I mean using a library of your programming language to store and read the embedding vectors. I will show an example of this solutions in depth in the next post.
When to use Embedded VectorSearch
- Small amounts of data
- price sensitive
- Import data before running the Lambda function
When not to use Embedded VectorSearch
- Additional features needed
- Large scale document size and count
Summary/Conclusion
Small RAG /GenAI solutions does not have to be expensive. Choosing the right solution can save a lot of money. On the other hand for an out-of-the-box solution, e.g. Kendra can get you up and running much faster.
While RAG solutions become more mature, you can choose from a variety of different solutions. You should consider using more fitting solutions, although you need time to learn how to use them. As each solution is up and running in a few hours, you can try them out and see what fits best. In a next post ill show you a complete Serverless solution which only uses AWS Lambda.
If you need developers and consulting to support your decision in your next GenAI project, don’t hesitate to contact us, tecRacer.
For more AWS development stuff, follow me on dev https://dev.to/megaproaktiv. Want to learn GO on AWS? GO here
Enjoy building!
Thanks to
Photo by Mukuko Studio on Unsplash
Photo by Lucas Hoang on Unsplash
See also
- bedrockembedding
- lastweekinaws: No, AWS, Aurora Serverless v2 Is Not Serverless
- Kendra pricing
- AWS Blog - Amazon OpenSearch Service’s vector database capabilities explained -OpenSearch pricing
- Reimagining Vector Databases for the Generative AI Era with Pinecone Serverless on AWS
- pgvector