Enhancing German Search in Amazon OpenSearch Service
Amazon OpenSearch Service, utilizing the robust OpenSearch framework, excels in search and analytics due to its remarkable speed and efficiency. Despite its strengths, the service’s default configurations might not be fully tailored to address the distinct linguistic challenges encountered in specific languages.
Take German, for example, known for its compound words like “Lebensversicherungsgesellschaft” (life insurance company). Standard tokenization in search technologies treats these compounds as single units, leading to less optimal search results. For improved accuracy, it’s important to index the components of these compounds separately – “Leben” (life), “Versicherung” (insurance), and “Gesellschaft” (company). This approach ensures more precise and effective search outcomes, particularly in languages like German with many compound words.

Combining Traditional Search with Advanced Filters
As of November 2023, OpenSearch supports an array of language options for the analyzer feature. These languages include: arabic, armenian, basque, bengali, brazilian, bulgarian, catalan, czech, danish, dutch, english, estonian, finnish, french, galician, german, greek, hindi, hungarian, indonesian, irish, italian, latvian, lithuanian, norwegian, persian, portuguese, romanian, russian, sorani, spanish, swedish, turkish, and thai.
However, when applying the German analyzer to our earlier example, it becomes evident that it struggles with compound words, failing to effectively break them down into simpler, searchable elements.
GET _analyze
{
"analyzer":"german",
"text": ["Lebensversicherungsgesellschaft."]
}
However, it returns only one token: lebensversicherungsgesellschaft. The built-in German analyzer lowercases the input and removes stop words like “und” (and), “oder” (or), “das” (this), which don’t contribute significantly to the search. Then it applies stemming, shortening words to make them more searchable. Unfortunately, it doesn’t adequately address the complexities of the German language.
To overcome this challenge, developers often turn to n-grams. This method breaks down text into smaller chunks of a specified size. For instance, in the sentence “The search is challenging,” applying 3-5 grams results in tokens:
the, sea, sear, searc, ear, earc, earch, arc, arch, rch, cha, chal, chall, hal, hall, halle, all, lle, llen, lleng, len, leng, lengi, eng, engi, engin, ngi, ngin, nging, gin, ging, ing
Although this can help, it often produces many false positives. It generates numerous meaningless (e.g., cha, ing) or misleading tokens (e.g., sea, ear), leading to bloated indexes and increased cluster load. This impacts search precision and operational costs.
The integration of dictionary_decompounder and synonym filters offers a more refined approach. These filters enhance precision and efficiency with German compound words, breaking them into simpler tokens. Additionally, synonym functionality expands the search’s reach by recognizing different expressions of similar concepts, further enhancing search accuracy and comprehensiveness.
Implementing Enhanced Filters in Amazon OpenSearch
The process of setting up these filters is straightforward and results in a significantly improved search experience. The decompound filters excel in breaking down complex compounds, while synonym filters expand search capabilities to include various expressions of similar concepts.
Prerequisites
- Amazon OpenSearch Service Cluster: You should have an Amazon OpenSearch Service cluster set up and running. If you’re not sure how to do this, Amazon provides a comprehensive guide to get you started.
- Access to AWS Management Console: You’ll need access to the AWS Management Console with the necessary permissions to manage Amazon OpenSearch Service.
Ensure you have these prerequisites in place before proceeding with the steps to implement decompound and synonym filters for German language search.
Step 1. Getting the dictionaries
To effectively implement decompound filters, begin by obtaining or creating a word list. For general-purpose text decompounding in German, consider using the solution developed by Uwe Schindler and Björn Jacke. This solution is available on GitHub, featuring a list of words here and hyphenator rules here. Note: To use it with Amazon OpenSearch Service Cluster, remove the second line in the file starting with <!DOCTYPE.
For synonyms, utilize the file from Openthesaurus.de, available here. To adapt it for OpenSearch, replace spaces with commas.
To facilitate your usage of these files, I have modified them accordingly and uploaded them to the repository.
-
de_DR.xml is a hyphenator rules file
-
german-decompound.txt is the german words dictionary for decompounding
-
german_synonym.txt is a synonym dictionary
Note license agreements, if you want to use these files.
Step 2. Adding dictionaries to Amazon OpenSearch Service
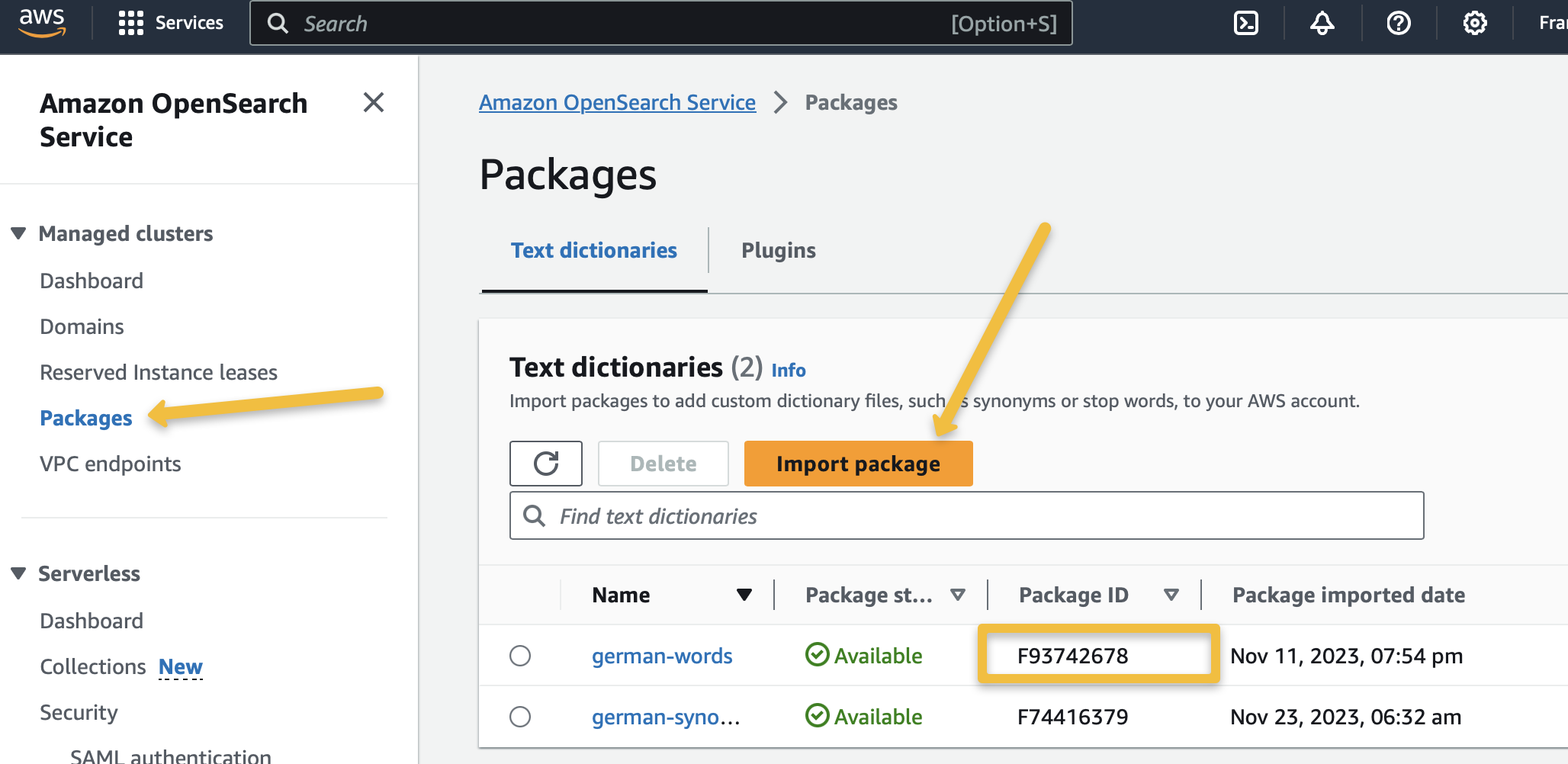
To use these files in your index, follow these steps:
- Create an S3 bucket and upload the files.
- Access the AWS Console for your managed OpenSearch cluster.
- Register your packages via the “Packages” link.
- Associate the packages with your OpenSearch cluster.
Notice: you can automate this step with IaC tools like Terraform or CDK.
Step 3: Creating an Index with a Custom German Analyzer in OpenSearch
After acquiring the necessary packages, you can incorporate these into your OpenSearch index by using their respective package IDs. Make sure to replace the placeholder IDs (FYYYYYYY for german_synonym.txt and FXXXXXXX for german-decompound.txt and FZZZZZZZ for de_DR.xml) with actual ones in your implementation.
To proceed with the index creation:
- Open the OpenSearch Dashboards and navigate to the DevTools section.
- In the DevTools console, input and execute the following queries to create your index with the custom German analyzer:
PUT /german_index
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"german_improved": {
"tokenizer": "standard",
"filter": [
"lowercase",
"german_decompounder",
"german_stop",
"german_stemmer"
]
},
"german_synonyms": {
"tokenizer": "standard",
"filter": [
"lowercase",
"german_decompounder",
"synonym",
"german_stop",
"german_stemmer"
]
}
},
"filter": {
"synonym": {
"type": "synonym",
"synonyms_path": "analyzers/FYYYYYYY"
},
"german_decompounder": {
"type": "hyphenation_decompounder",
"word_list_path": "analyzers/FXXXXXXX",
"hyphenation_patterns_path": "analyzers/FZZZZZZZ",
"only_longest_match": false,
"min_subword_size": 3
},
"german_stemmer": {
"type": "stemmer",
"language": "light_german"
},
"german_stop": {
"type": "stop",
"stopwords": "_german_",
"remove_trailing": false
}
}
}
}
},
"mappings": {
"properties": {
"paragraph": {
"type": "text",
"analyzer": "german_improved",
"search_analyzer": "german_synonyms"
}
}
}
}
In this setup, we’re deploying a specialized approach to handling German language text in OpenSearch by defining two distinct analyzers: ‘german_improved’ for indexing and ‘german_synonyms’ for searching. This decision is aimed at improving both storage and search efficiency.
- Indexing with ‘german_improved’ Analyzer: During indexing, we utilize the ‘german_improved’ analyzer. This analyzer incorporates a standard tokenizer and a series of filters including lowercase, german_decompounder, german_stop, and german_stemmer. The primary goal here is to decompose and standardize the text, enhancing the consistency and relevancy of the index. Importantly, this analyzer deliberately excludes the use of a synonyms filter. The rationale behind this is to maintain a more streamlined and compact index, which focuses on the core linguistic elements of the German language without the additional complexity and storage overhead of synonyms.
- Searching with ‘german_synonyms’ Analyzer: For the search phase, we switch to the ‘german_synonyms’ analyzer. This analyzer shares the same foundational components as ‘german_improved’ but adds a crucial layer - the synonym filter. This inclusion dramatically enhances search flexibility and relevance by considering a range of synonymous terms, thereby broadening the search scope without compromising precision.
- Efficiency and Performance: One of the notable outcomes of this methodology is the significant reduction in index size – at least 50% smaller compared to using ngrams. The extent of this reduction can vary based on the ngram range. This leaner index not only conserves storage space but also contributes to faster search operations. Additionally, by reserving the use of synonyms for the search phase only, we ensure that the index remains focused and efficient, while searches become more inclusive and contextually aware.
- Custom Filters and Decompounding: The custom filters like ‘german_decompounder’, ‘german_stemmer’, and ‘german_stop’ are tailored to address the unique characteristics of the German language, such as compound words and varied inflections. The decompounder, in particular, is a powerful tool for breaking down complex German compounds into more searchable elements, further refining both indexing and searching processes.
By employing this dual-analyzer strategy, we achieve an optimal balance between a lean, efficient index and a robust, nuanced search capability, tailored specifically for the German language context.
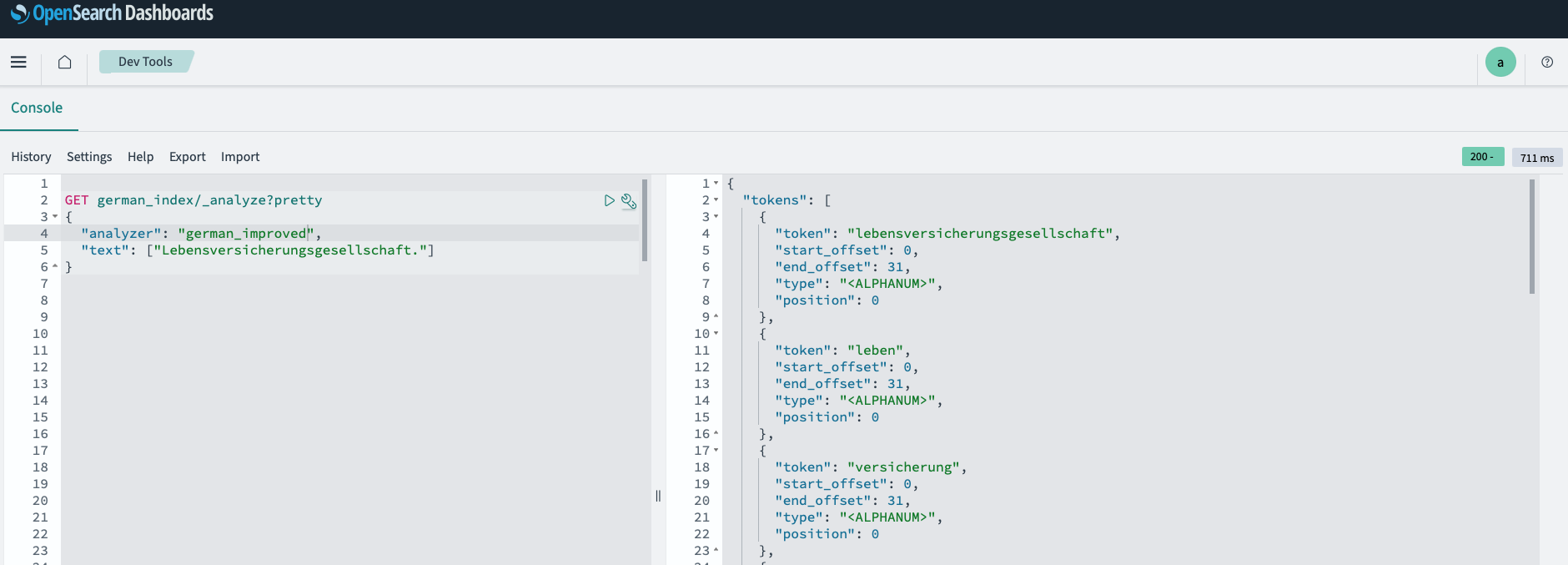
- Now you can try the “german_improved” analyzer:
GET german_index/_analyze?pretty
{
"analyzer": "german_improved",
"text": ["Lebensversicherungsgesellschaft."]
}
- You can add some documents to the search and further experiment with the new index.
PUT /german_index/_doc/1
{
"paragraph": "Eine Alsterrundfahrt bietet eine einzigartige Gelegenheit, die idyllische Landschaft und die städtische Schönheit Hamburgs vom Wasser aus zu erleben."
}
Now, you will see that the search will retrieve this document if you use the synonym “Reise” (meaning travel, journey, trip) for a part of the word “Alsterrundfahrt” (Alster river round trip), specifically “Rundfahrt” (round trip).
GET german_index/_search
{
"query": {
"match": {
"paragraph": "Reise"
}
}
}
Conclusion
The enhancements in Amazon OpenSearch with custom text analyzers demonstrate its adaptability and efficiency in handling German search challenges. This approach, showcasing a nuanced understanding of language intricacies, is invaluable for businesses and developers dealing with full-text search, enhancing both user experience and search relevance.
For those seeking alternatives, exploring semantic search techniques and hybrid approaches can be beneficial. Semantic search delves deeper into understanding the context and meaning behind user queries, offering a more sophisticated level of search accuracy. A hybrid approach, combining traditional keyword search with semantic capabilities, can further refine results, especially in complex search scenarios.
We encourage businesses and developers to explore these enhancements in their Amazon OpenSearch deployments to experience firsthand the improved search capabilities and operational efficiencies.
We at tecRacer, can help you with tailored OpenSearch Service optimisation. As an Amazon OpenSearch Service Delivery Partner, we offer specialized support in infrastructure design, automation of your cluster deployment and management, performance monitoring, and query optimization.
— Alexey