Stop LLM/GenAI hallucination fast: Serverless Kendra RAG with GO
RAG is a way to approach the “hallucination” problem with LLM: A contextual reference increases the accuracy of the answers. Do you want to use RAG (Retrieval Augmented Generation) in production? The Python langchain library may be too slow for your production services. So what about serverless RAG in fast GO Lambda?
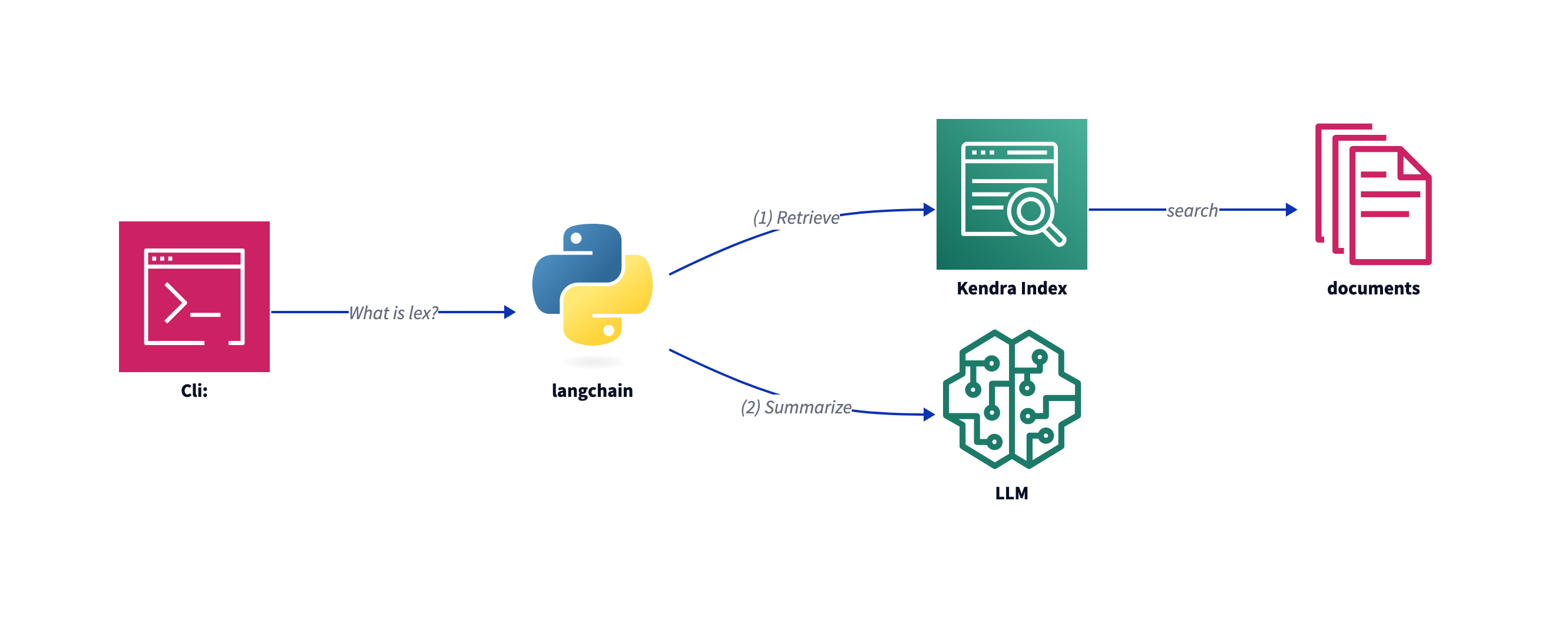
The AWS RAG sample solution
In evaluating whether a technical solution is suitable, the focus is on the simplicity of development. So, the AWS sample uses the well-known langchain library and a streamlit server for the chat sample.
Shifting to production ready solutions, the focus goes on speed and scalability.
In Quickly build high-accuracy Generative AI applications on enterprise data using Amazon Kendra, LangChain, and large language models a StreamLit Python Server is used. See kendra_retriever_samples for Code.
As this is a good choice for working with low volume data science and LLM projects, a serverless solution does scale better. in Simplify access to internal information using Retrieval Augmented Generation and LangChain Agents a few examples are shown.
And with a serverless solution we enter the polyglott world and can decide on the best language for the job. So what about GO?
RAG with langchain, OpenAI and Amazon Kendra
The sample server uses Python and the langchain library. However, despite its functionality, speed and memory consumption could be better.
To check this assumption, I test the speed of the solution. I use just the langchain library in kendra_retriever_open_ai.py from amazon-kendra-langchain-extensions/kendra_retriever_samples.
Measure speed and size
Python Speed
The Kendra index from the AWS sample solution queries some AWS documentation. So a question should be about that topic.
Therefore to measure speed I use a single query “What is lex?” and perform it 10 times to reduce statistical randomness. This is only done locally, but should give a good measurement for lambda cold starts.
The test calls python3 kendra_chat_open_ai.py 10 times.
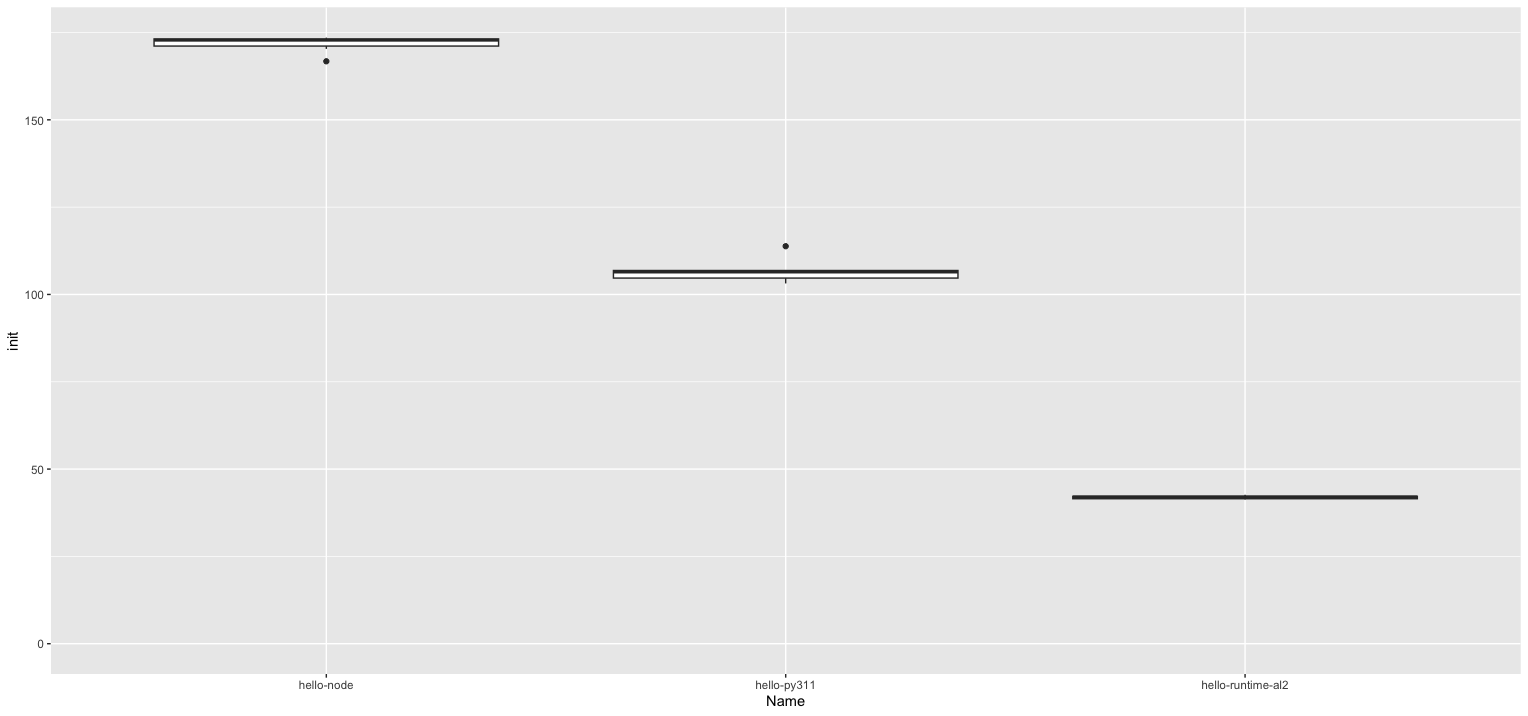
./test.sh 35,19s user 7,26s system 57% cpu 1:13,63 total
So time measuring rod is 73 seconds per 10 iterations.
Python Size
The app kendra_retriever_open_ai.py itself is only a few K large.
Most of the size goes to the pleora of libraries:
499M .venv
108K .venv/bin
490M .venv/lib
So size measure is around 490 M.
Production
Shifting to Lambda/GO
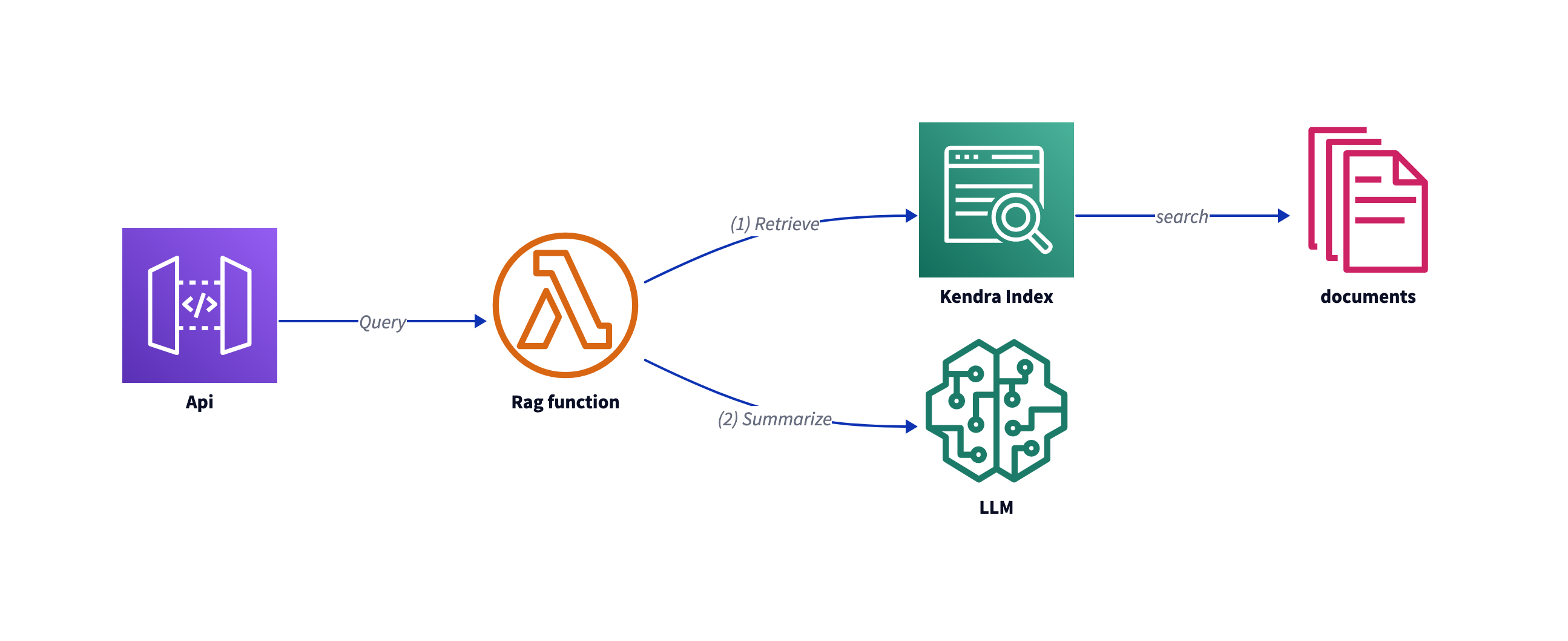
The problem with Python Lambda is the cold start, see custom-runtime-on-amazon-linux-2-go-outperforms-node-3x-and-python-2x-with-aws-lambda-cold-start-time.html. Also what often is forgotten is the cost of updating the Lambda Python runtime over the years. With the GO backward compatibility promise you have less cost of code maintenance.
See the comparism of cold starts Node vs Python vs GO custum runtime.
Implementation in Python
To reproduce the behaviour of kendra_retriever_open_ai.py you have to understand the Langchain library. The general behaviour is:
- Retrieve Kendra data
- Generate Prompt with langchain “stuff” chain
- Call LLM for inference
The steps in Python are:
- Retrieve Kendra data
see .venv/lib/python3.11/site-packages/langchain/retrievers/kendra.py
- / 3) in
kendra_retriever_open_ai.py:
llm = OpenAI(batch_size=5, temperature=0, max_tokens=300, model="gpt-3.5-turbo")
retriever = AmazonKendraRetriever(index_id=kendra_index_id,region_name=region)
The llm is initialized with the OpenAI model and the retriever with the Kendra index.
The the chain is started
RetrievalQA.from_chain_type(
llm,
chain_type="stuff",
retriever=retriever,
chain_type_kwargs=chain_type_kwargs,
return_source_documents=True
)
and the results are printed.
result = chain(prompt)
Resulting in:
python kendra_chat_open_ai.py
Hello! How can I help you?
Ask a question, start a New search: or CTRL-D to exit.
> QueryText: what is lex?
Amazon Lex is an AWS service for building conversational interfaces for applications using voice and text.
With Amazon Lex, the same conversational engine that powers Amazon Alexa is now available to
any developer, enabling them to build sophisticated, natural language chatbots into their new and existing applications.
Amazon Lex provides the deep functionality and flexibility of natural language understanding (NLU)
and automatic speech recognition (ASR) so developers can
build highly engaging user experiences with lifelike, conversational interactions, and create new categories of products.
Sources:
https://docs.aws.amazon.com/lex/latest/dg/what-is.html
https://docs.aws.amazon.com/lex/latest/dg/security-iam.html
https://docs.aws.amazon.com/lex/latest/dg/security-iam.html
Implementing in GO
- Retrieve data from kendra
I use the Amazon Kendra API directly:
parameters := &kendra.RetrieveInput{
IndexId: aws.String("1d936da5-4a20-462c-826f-bdddaa59e5e8"),
QueryText: aws.String("What is lex?"),
}
// do retrieve
resp, err := client.Retrieve(context.Background(), parameters)
- Stuff/Langchain
In the end this should be a template solution, but to measure timing I just concat strings:
prompt := pre
max := 3
for i, doc := range query.ResultItems {
if i >= max {
break
}
prompt = prompt + " Document Title: " + *doc.DocumentTitle
prompt = prompt + " Document Excerpt: " + *doc.Content
}
So some checks and using templates will add a few microseconds to the timing.
- OpenAI
OpenAI just uses a REST api, for the request there is a commnunity solution: github.com/sashabaranov/go-openai.
With that I call the Chat completion API call of openAI
resp, err := client.CreateChatCompletion(
context.Background(),
openai.ChatCompletionRequest{
Model: openai.GPT3Dot5Turbo,
MaxTokens: 300,
Messages: []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleAssistant,
Content: prompt,
},
},
Temperature: 0,
},
)
GO Size
With GO you get a compile binary with all libraries included:
ls -lkh dist
total 9728
-rwxr-xr-x@ 1 gernotglawe staff 9,5M 15 Sep 18:03 rag
So overall size is 9,5 M. Compared to 490M, this is about 50 times smaller.
With ARM bases Lambda it is even smaller:
ls -lkh dist
total 9348
-rwxr-xr-x@ 1 gglawe staff 6,6M 20 Sep 18:34 bootstrap
-rw-r--r--@ 1 gglawe staff 2,6M 20 Sep 18:34 bootstrap.zip
GO Speed

GO Run:
Amazon Lex is an AWS service for building conversational interfaces for applications using voice and text.
It allows developers to build sophisticated, natural language chatbots into their new and existing applications,
using the same conversational engine that powers Amazon Alexa. With Amazon Lex, developers can create highly
engaging user experiences with lifelike, conversational interactions and
take advantage of natural language understanding (NLU) and automatic speech recognition (ASR) capabilities.
Additionally, Amazon Lex enables developers to quickly build conversational chatbots.
Sources:
https://docs.aws.amazon.com/lex/latest/dg/what-is.html
https://docs.aws.amazon.com/lex/latest/dg/security-iam.html
https://docs.aws.amazon.com/lex/latest/dg/security-iam.html
And 10 iterations:
./test.sh 0,11s user 0,13s system 0% cpu 46,088 total
73 seconds/46 seconds = 1,58
So speed is about 46 seconds, which is about 50% faster. The 8% is rounded because there is still some checking etc to be done.
Moving to Lambda
A few considerations:
Language
Note the default language of the kendra data source. You need to set the language of the query to the same language. For German you need to:
parameters := &kendra.RetrieveInput{
IndexId: &index,
QueryText: &query,
AttributeFilter: &types.AttributeFilter{
AndAllFilters: []types.AttributeFilter{
{
EqualsTo: &types.DocumentAttribute{
Key: aws.String("_language_code"),
Value: &types.DocumentAttributeValue{
StringValue: aws.String("de"),
},
},
},
},
},
}
In Python it would look like :
attribute_filter_json='''
{ "AndAllFilters": [
{
"EqualsTo": {
"Key": "_language_code",
"Value": {
"StringValue": "de"
}
}
}
]
}
'''
attribute_filter = json.loads(attribute_filter_json)
retriever = AmazonKendraRetriever(index_id=kendra_index_id, attribute_filter = attribute_filter)
Timeout
The default timeout of lambda is 3 seconds. As the results from the LLM api can take some time, you need to increase the timeout to at least a minute.
A typical log entry looks like this:
2023/09/20 16:34:53 INFO Lambda start
2023/09/20 16:34:53 INFO Kendra start
2023/09/20 16:34:54 INFO Kendra end
2023/09/20 16:34:54 INFO OpenAI start
2023/09/20 16:35:15 INFO OpenAI end
...LLM output...
2023/09/20 16:35:15 INFO Lambda end
AWS Managed Role
As the Kendra retrieve API is quite new, the AWS managed role does not have the permission to call it. You need to add the permission to the role.
Conclusion
Langchain great for testing several choices. When you have found your model and type of langchain, you can optimize for size and speed. With GO you can get 50 times less size and 50% faster speed.
If you need consulting for your serverless project, don’t hesitate to get in touch with the sponsor of this blog, tecRacer.
For more AWS development stuff, follow me on dev https://dev.to/megaproaktiv. Want to learn GO on AWS? GO here