Glue Crawlers don’t correctly recognize Ion data - here’s how you fix that
Amazon Ion is one of the data serialization formats you can use when exporting data from DynamoDB to S3. Recently, I tried to select data from one of these exports with Athena after using a Glue Crawler to create the schema and table. It didn’t work, and I got a weird error message. In this post, I’ll show you how to fix that problem. If you’re not familiar with Ion yet, check out my recent blog post introducing it for more details.
First, I should explain why I want to do this. DynamoDB is a NoSQL database that is great for data with relatively static access patterns. It handles vast amounts of data at ease with predictable latency. That’s great for OLTP workloads, but analytics workloads typically have anything but static access patterns. Because of that, I decided to export the data to S3 and use a service that allows me to throw SQL against data in S3 to fulfill my analytics queries: Athena.
For Athena to be able to read the data, we need a table in the Glue Data Catalog that holds information about the columns and data structures, as well as the storage location and information about how the data should be read or written. If you don’t feel like populating all that information manually, you can use a Crawler to sift through the data in S3 and create tables based on it. That’s what I tried to do. I deployed and ran a crawler that set up the table for me. Everything looked great at first glance.
When I queried the data from Athena, it responded with this beautiful error message:
HIVE_UNSUPPORTED_FORMAT: Unable to create input format
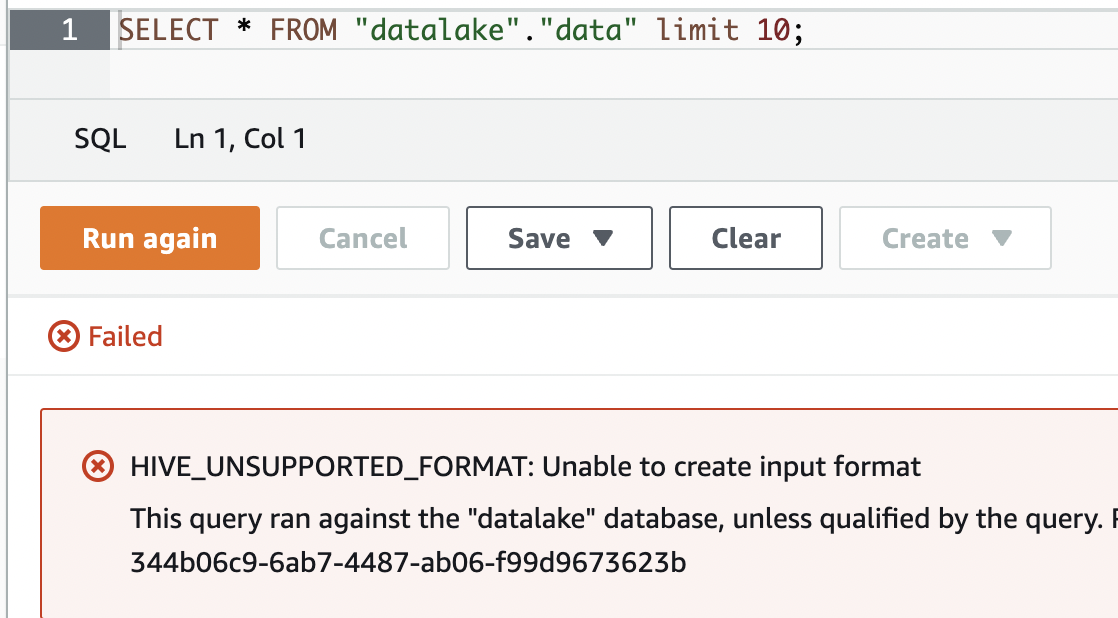
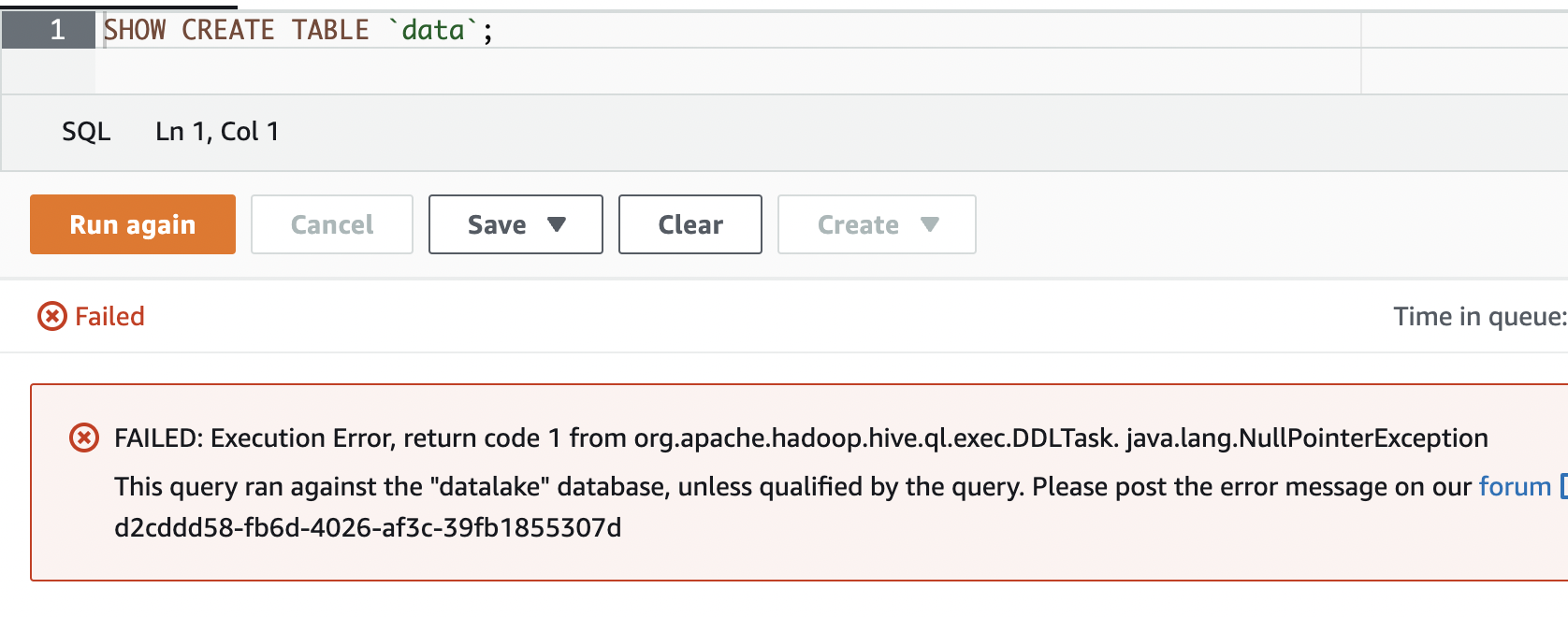
Naturally, I tried looking at the table in Athena to see what was going on, but that wasn’t very helpful. It wouldn’t even show me the create table statement:
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. java.lang.NullPointerException
At this point, I got a little annoyed. I looked at the table in Glue and got confused. I saw the “Classification: ion” label, which made it seem like the Crawler hat recognized the data format. In the schema below, it had also correctly identified the columns and data types in the files.
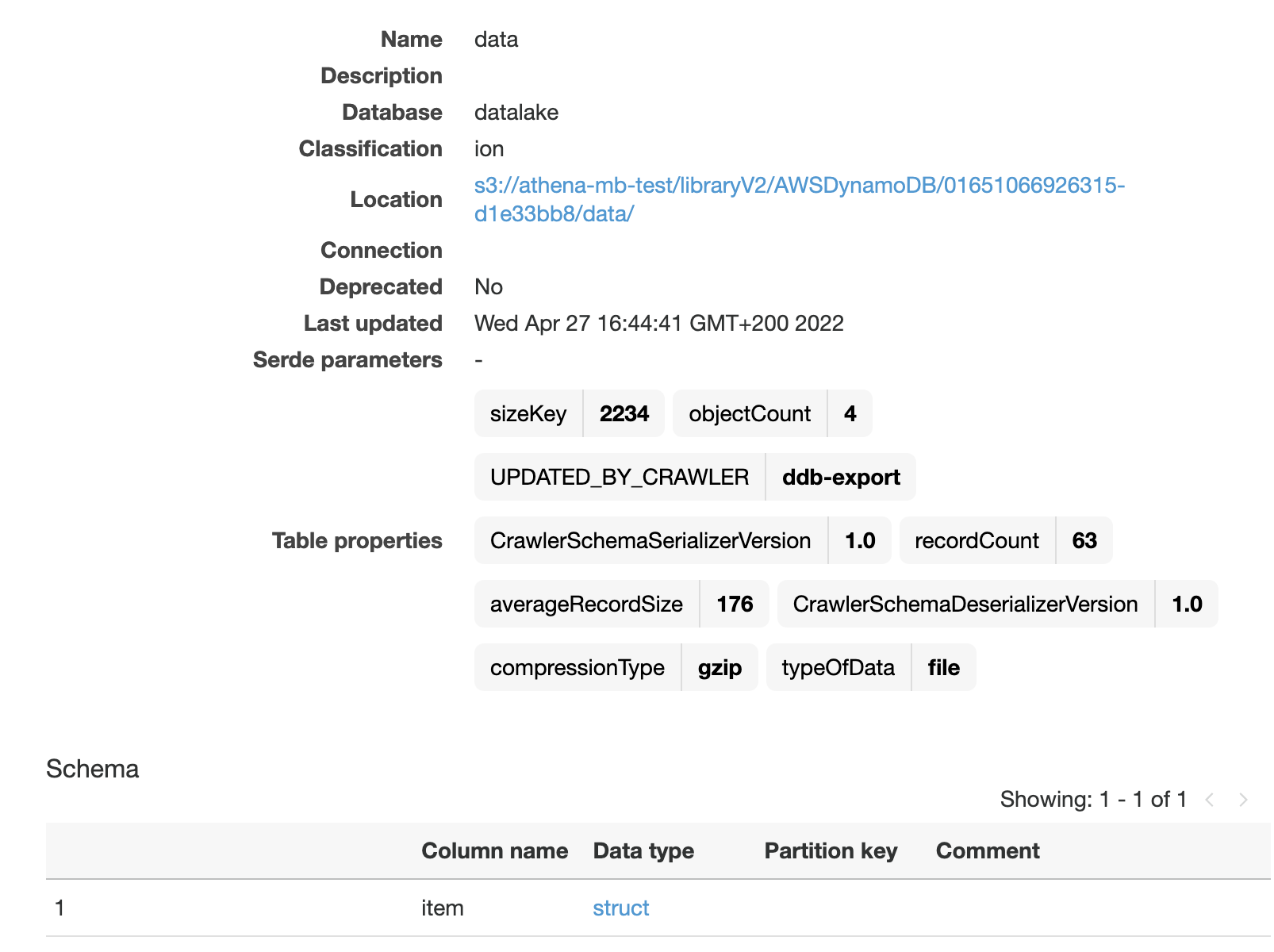
For whatever reason, essential information is missing, though - there is no Serde (Serializer / Deserializer) configured, which would tell the system how the data can be read. A quick look at the documentation showed me that the serializer information just consists of three key-value pairs which are static and in no way computed. I don’t understand why the Crawler failed to add them.
To fix this, you simply add the values in the “Edit Table” dialog in Glue, and it should look like this:
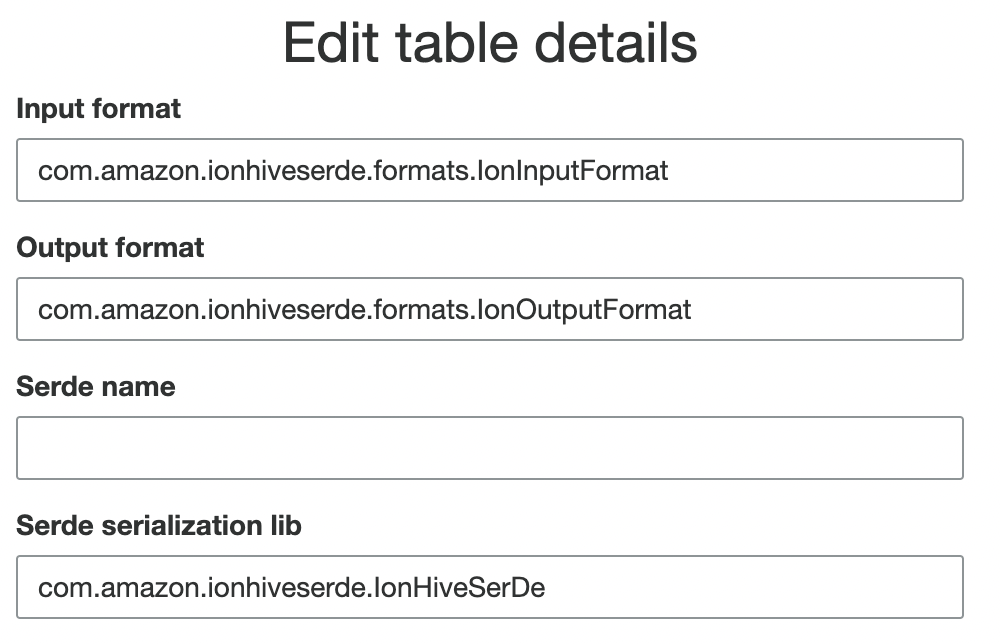 Here’s the copy-paste friendly version:
Here’s the copy-paste friendly version:
Input Format:
com.amazon.ionhiveserde.formats.IonInputFormat
Output Format:
com.amazon.ionhiveserde.formats.IonOutputFormat
Serde serialization lib
com.amazon.ionhiveserde.IonHiveSerDe
Afterward, we can rerun the original statement and should now see data in Athena:
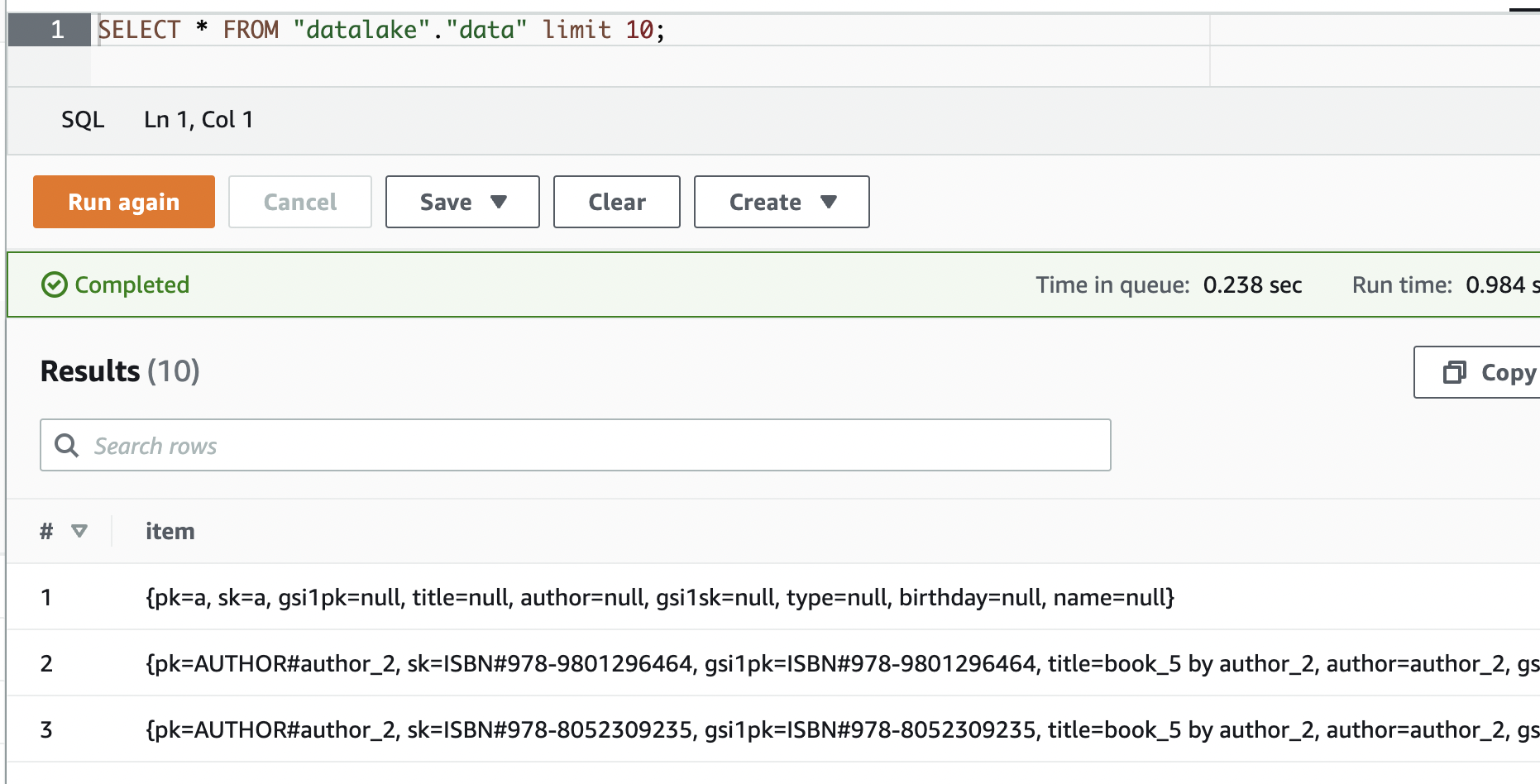
I don’t understand why the Crawler doesn’t add this basic information, but after talking to AWS support, it seems this is a known error, and the service team is aware of it. If or when they’ll fix it - as usual, no ETA.
Hopefully, you learned something from this post. I’m looking forward to any questions, feedback, or concerns.
— Maurice
Title Photo by Torbjørn Helgesen on Unsplash