Building QuickSight Datasets with CDK - Athena
In a previous blog post (Building QuickSight Datasets with CDK - S3) we had a look at how files in S3 could be loaded into a QuickSight dataset. In practice data in S3 is often accessed using Athena. In this new blog post we will see how to build a QuickSight Dataset with CDK directly making use of Athena.
Preparation steps
First thing first, we need the data available at the right place. We will use the following structure in S3.
your-bucket-name/
├── tables/
│ ├── titanic/
│ | └── titanic.csv
│ ├── ...
│ | └── ...
│ └── <table-n>
│ └── <file-n>.csv
└── athena-results/
├── ...
├── d4737bbd-5ab5-4101-be12-a24f289c8e20.csv.metadata
└── d4737bbd-5ab5-4101-be12-a24f289c8e20.csv
Upload the file titanic.csv (data/titanic.csv in the companion) to the following location: s3://$YOUR_BUCKET_NAME/tables/titanic/titanic.csv.
Create the titanic table in Athena with the following SQL and make sure to replace $YOUR_BUCKET_NAME with the name of your actual bucket.
CREATE EXTERNAL TABLE `titanic`(
`survived` bigint,
`pclass` bigint,
`name` string,
`sex` string,
`age` double,
`siblings/spouses aboard` bigint,
`parents/children aboard` bigint,
`fare` double)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://$YOUR_BUCKET_NAME/tables/titanic/'
TBLPROPERTIES (
'CrawlerSchemaDeserializerVersion'='1.0',
'CrawlerSchemaSerializerVersion'='1.0',
'areColumnsQuoted'='false',
'averageRecordSize'='66',
'classification'='csv',
'columnsOrdered'='true',
'compressionType'='none',
'delimiter'=',',
'objectCount'='1',
'recordCount'='670',
'sizeKey'='44225',
'skip.header.line.count'='1',
'typeOfData'='file')
The table titanic should now be available in Athena within the default database.
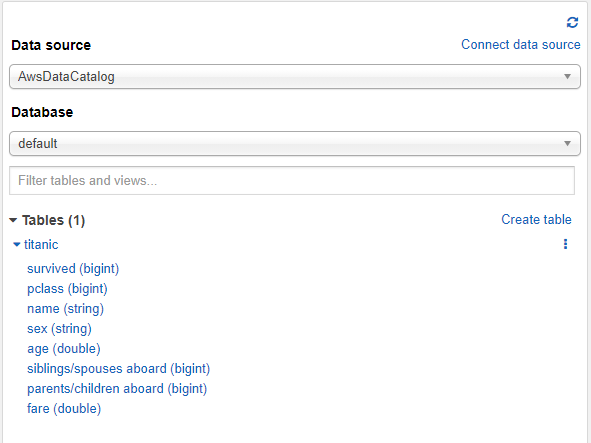
Permissions
We grant the QuickSight service role read access to the data (tables/* ) and read/write access for athena query results (athena-results/* ).
qs_service_role_names = [
"aws-quicksight-service-role-v0",
"aws-quicksight-s3-consumers-role-v0",
]
athena_output_prefix = "athena-results"
qs_managed_policy = iam.CfnManagedPolicy(
self,
"QuickSightPolicy",
managed_policy_name="QuickSightDemoAthenaS3Policy",
policy_document=dict(
Statement=[
dict(
Action=["s3:ListAllMyBuckets"],
Effect="Allow",
Resource=["arn:aws:s3:::*"],
),
dict(
Action=["s3:ListBucket"],
Effect="Allow",
Resource=[
f"arn:aws:s3:::{bucket_name}",
],
),
dict(
Action=[
"s3:GetObject",
"s3:List*",
],
Effect="Allow",
Resource=[
f"arn:aws:s3:::{bucket_name}/tables/*",
],
),
dict(
Action=[
"s3:GetObject",
"s3:List*",
"s3:AbortMultipartUpload",
"s3:PutObject",
],
Effect="Allow",
Resource=[
f"arn:aws:s3:::{bucket_name}/{athena_output_prefix}/*",
],
),
],
Version="2012-10-17",
),
roles=qs_service_role_names,
)
In case the deployment fails due to the service role aws-quicksight-s3-consumers-role-v0 not been found, just remove it from the list qs_service_role_names.
As principal you can use QuickSight users (e.g. arn:aws:quicksight:${Region}:12345678910:user/default/username) or QuickSight groups (e.g. arn:aws:quicksight:${Region}:12345678910:group/default/groupname).
We use readonly permissions for both the data source and dataset.
qs_data_source_permissions = [
quicksight.CfnDataSource.ResourcePermissionProperty(
principal=qs_principal_arn,
actions=[
"quicksight:DescribeDataSource",
"quicksight:DescribeDataSourcePermissions",
"quicksight:PassDataSource",
],
),
]
qs_dataset_permissions = [
quicksight.CfnDataSet.ResourcePermissionProperty(
principal=qs_principal_arn,
actions=[
"quicksight:DescribeDataSet",
"quicksight:DescribeDataSetPermissions",
"quicksight:PassDataSet",
"quicksight:DescribeIngestion",
"quicksight:ListIngestions",
],
)
]
Data sources
The only parameter specific to Athena data sources is the workgroup.
We need to make sure the selected workgroup stores queries results in a location accessible to the QuickSight service role. We therefore define the following Athena workgroup to the data within our bucket at the location athena-prefix/.
athena_workgroup_name = f"athena-titanic-wg"
athena_workgroup = athena.CfnWorkGroup(
self,
"Workgroup",
name=athena_workgroup_name,
work_group_configuration=athena.CfnWorkGroup.WorkGroupConfigurationProperty(
result_configuration=athena.CfnWorkGroup.ResultConfigurationProperty(
output_location=f"s3://{bucket_name}/{athena_output_prefix}/",
encryption_configuration=athena.CfnWorkGroup.EncryptionConfigurationProperty(
encryption_option="SSE_S3"
),
)
),
recursive_delete_option=True,
)
We now have a workgroup and can define our data source. When creating the data source, QuickSight will check access by creating and reading a file in the workgroup output folder. We add the managed policy as dependency of the data source to make sure this happens after permissions have been granted.
qs_athena_data_source_name = "athena-titanic"
qs_athena_data_source = quicksight.CfnDataSource(
self,
"AthenaDataSource",
name=qs_athena_data_source_name,
data_source_parameters=quicksight.CfnDataSource.DataSourceParametersProperty(
athena_parameters=quicksight.CfnDataSource.AthenaParametersProperty(
work_group=athena_workgroup_name
)
),
type="ATHENA",
aws_account_id=self.account,
data_source_id=qs_athena_data_source_name,
ssl_properties=quicksight.CfnDataSource.SslPropertiesProperty(
disable_ssl=False
),
permissions=qs_data_source_permissions,
)
qs_athena_data_source.add_depends_on(qs_managed_policy)
Datasets
The datatype mapping between Quicksight and Athena is as follows:
{
"STRING": ["VARCHAR","STRING"] ,
"INTEGER": ["BIGINT","INTEGER","BOOLEAN","TINYINT","SMALLINT","BOOLEAN"],
"DATETIME": ["DATE","TIMESTAMP"],
"DECIMAL": ["FLOAT","DOUBLE","DECIMAL"],
"JSON": ["STRUCT"]
}
When working with databases as data source .
- We can either create a dataset by directly loading a table “as is” or by using a SQL query
- Amazon QuickSight will generate a timeout after 2 minutes if the data is loaded in direct query mode
- QuickSight, as of now, has issues handling NaN values that could be generated by our SQL query
Relational table
Relational table are used in QuickSight to directly load database tables or views into datasets.
qs_athena_dataset_titanic_physical_table = (
quicksight.CfnDataSet.PhysicalTableProperty(
relational_table=quicksight.CfnDataSet.RelationalTableProperty(
data_source_arn=qs_athena_data_source.attr_arn,
input_columns=[
quicksight.CfnDataSet.InputColumnProperty(
name="Survived", type="INTEGER"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Pclass", type="INTEGER"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Name", type="STRING"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Sex", type="STRING"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Age", type="DECIMAL"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Siblings/Spouses Aboard", type="INTEGER"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Parents/Children Aboard", type="INTEGER"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Fare", type="DECIMAL"
),
],
catalog="AWSDataCatalog",
schema=athena_database_name,
name="titanic",
)
)
)
We can now build the QuickSight dataset:
qs_import_mode = "SPICE"
qs_dataset_titanic_name = "athena-titanic-ds"
qs_athena_dataset_titanic_raw = quicksight.CfnDataSet(
self,
f"Dataset-athena-titanic",
import_mode=qs_import_mode,
name=qs_dataset_titanic_name,
aws_account_id=self.account,
data_set_id=qs_dataset_titanic_name,
physical_table_map={
"athena-titanic-table": qs_athena_dataset_titanic_physical_table
},
permissions=qs_dataset_permissions,
)
Custom SQL
When using custom SQL to create a dataset, unless queried tables are available in the default database, we have to make sure to include the corresponding database.
sql_statement = f"""
SELECT
Survived,
Name,
Sex,
"Siblings/Spouses Aboard"+"Parents/Children Aboard" AS Related
FROM {athena_database_name}.titanic
"""
qs_athena_dataset_titanic_physical_table_sql = (
quicksight.CfnDataSet.PhysicalTableProperty(
custom_sql=quicksight.CfnDataSet.CustomSqlProperty(
name="titanic-sql",
data_source_arn=qs_athena_data_source.attr_arn,
sql_query=sql_statement,
columns=[
quicksight.CfnDataSet.InputColumnProperty(
name="Survived", type="INTEGER"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Name", type="STRING"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Sex", type="STRING"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Related", type="INTEGER"
),
],
),
)
)
qs_dataset_titanic_sql_name = "athena-titanic-sql-ds"
qs_athena_dataset_titanic_sql = quicksight.CfnDataSet(
self,
f"Dataset-athena-titanic-sql",
import_mode=qs_import_mode,
name=qs_dataset_titanic_sql_name,
aws_account_id=self.account,
data_set_id=qs_dataset_titanic_sql_name,
physical_table_map={
"athena-titanic-table-sql": qs_athena_dataset_titanic_physical_table_sql
},
permissions=qs_dataset_permissions,
)
Code
The full code is available in the companion on Github.
If everything went smoothly you should now be able to see the dataset athena-titanic-ds in QuickSight.
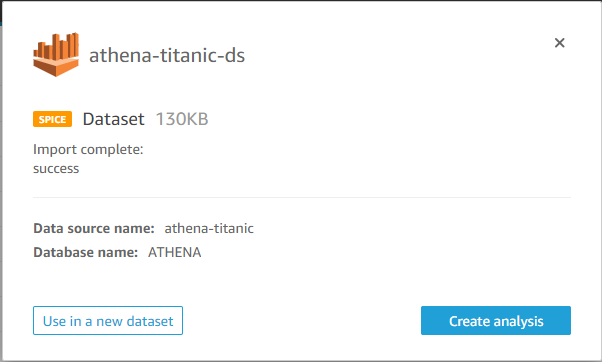
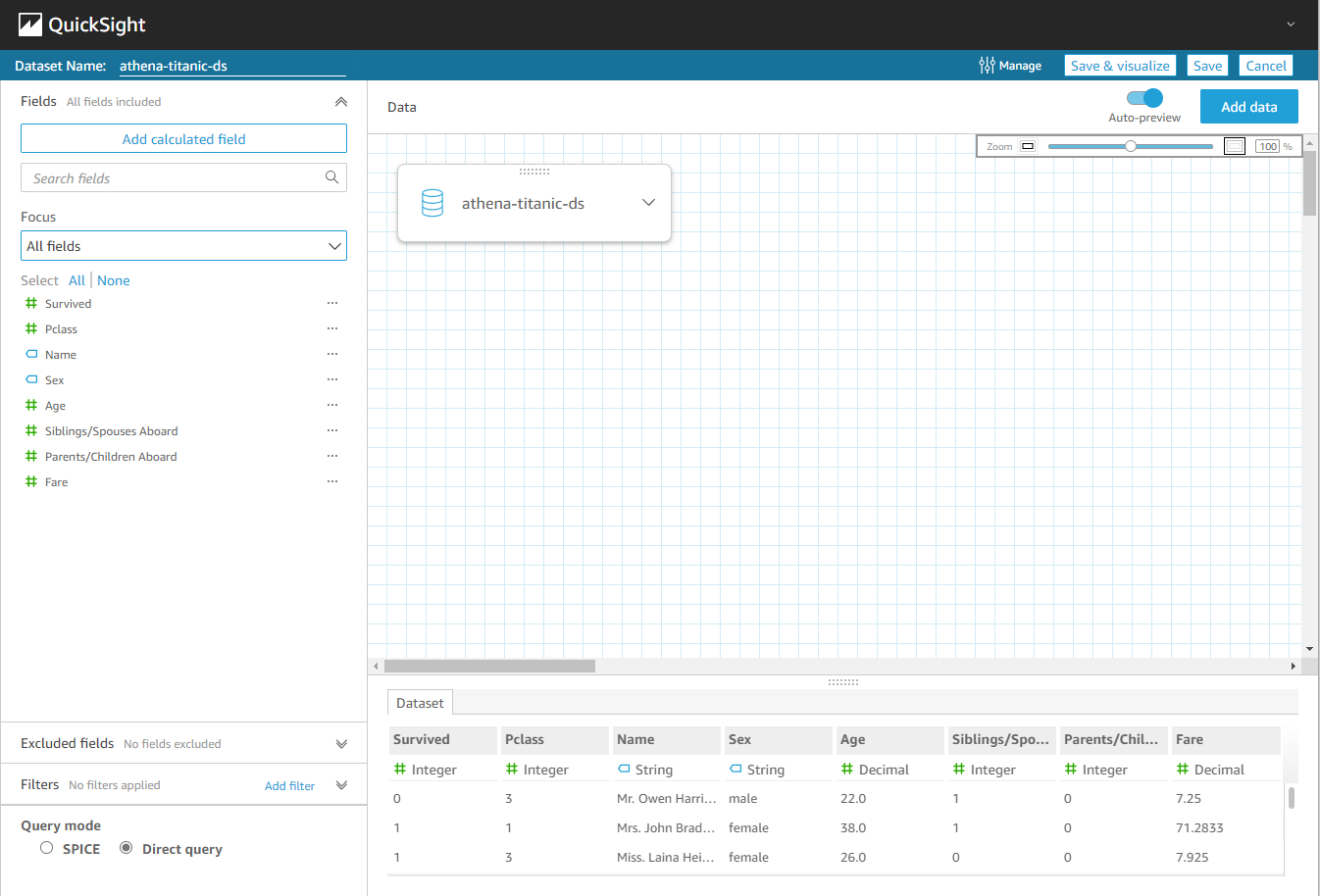
Clicking on the dataset and selecting the option Use in a new dataset should allow you to preview it without directly creating an analysis.
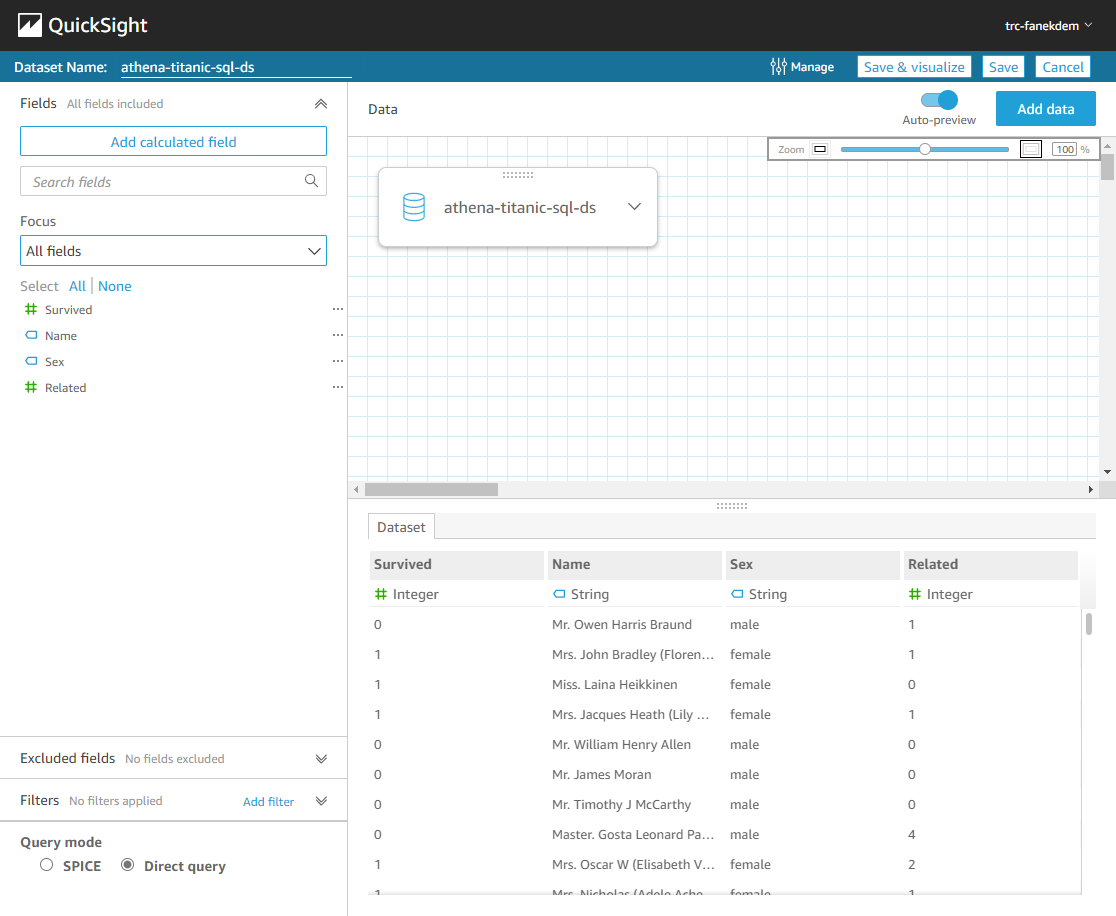
The dataset athena-titanic-ds should be available as well.
Summary
In this post we briefly prepared an Athena table and learned how to build a Quicksight dataset with CDK using Athena as data source. We experimented with both table loading (RelationalTable) and custom SQL.
As with QuickSight Datasets built with S3 as data source, this may seem like much work when compared to directly using the QuickSight web console. However, keep in mind that the goal is to be able to automate it.
References
- https://docs.aws.amazon.com/cdk/api/v1/docs/aws-quicksight-readme.html
- https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-quicksight-dataset.html
- https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-quicksight-datasource.html
- https://docs.aws.amazon.com/quicksight/latest/user/data-source-limits.html