Using CloudFormation Modules for Serverless Standard Architecture
This content is more than 4 years old and the cloud moves fast so some information may be slightly out of date.
Serverless - a Use Case for CloudFormation Modules?
Let´s agree to “infrastructure as code” is a good thing. The next question is: What framework do you use? To compare the frameworks, we have the tRick-benchmark repository, where we model infrastructure with different frameworks.
Here is a walk through how to use CloudFormation Modules. This should help you to compare the different frameworks.
In the trick serverless-standard benchmark, we compare AWS-SAM, the CDK and now CloudFormation modules.

This is the serverless-standard architecture:
- a S3 bucket which triggers an event for incoming objects to
- a Lambda function with a role. That functions logs output to
- CloudFormation log and writes the key to
- a DynamoDB
For simplicity, I have left out the bucket, but with the modules Lambda, DynamoDB and roles, it should be easy to add more modules.
Now I want to show you how to use the CloudFormation module service in a complete walkthrough.
Preparation
At first we need some additional software.
CloudFormation (cfn) Command Line Interface
The “CloudFormation Command Line Interface” is not an command line for CloudFormation, as the name may suggest. It can only be used on cfn resources and modules. See the documentation.
Prerequisites
AWS CLI
The AWS cli must be installed, see the installation documentation
You may check this with:
aws --version
This should give something like:
aws-cli/2.1.5 Python/3.9.0 Darwin/19.6.0 source/x86_64 prompt/off
You need version 2 of the cli, so aws-cli/2.x.
If you only want to use modules, not resource types, you do not have to install the language plugins of cfn modules.
Taskfile
If you do the prepared walkthrough, you need “Task” as a makefile tool, which can be found here
On mac/linux with Homebrew this should install it:
brew install go-task/tap/go-task
Installation
The cfn cli can be installed
pip3 install cloudformation-cli
or upgraded
pip3 install --upgrade cloudformation-cli
with pip.
Here is the “AWS CloudFormation CLI” on pypi for more details.
You may check the installation with:
cfn --version
The output should be something like:
cfn 0.2.1
If you get a permission error, you could try the hard way sudo pip3 install cloudformation-cli. - In the cloud9 environment from December I got a permission error. Usually installing with root is not the best way.
Confusing Versioning
The AWS documentation talks about “CFN-CLI 2.0”, but the version 2.0 has the cli version 0.2.1.
Confused? Then look at the date of the Introducing AWS CloudFormation modules blogpost, which is 24 Nov 2020 and compare it with the Document History of the CFN-CLI which was last updated November1 4, 2019.

But in the heat of reinvent, a few numbers can go wrong. ;)
Walk through
Installing the cfn modules
- Start cloud9
Or any other development environment. With cloud9 you have the advantage of an defined environment.
- Checkout repository
git clone https://github.com/tecracer/tRick-benchmarks.git
cd tRick-benchmarks/
cd serverless-standard/
cd cloudformation/
Now you have all the source files
- Install
task
brew install go-task/tap/go-task
This is the makefile app I am using for the predefined scripts. Because I really like it the installation is mentioned twice. :)
- Show all tasks
task -l
Each single task in the Taskfile is documented with a description in the desc:attribute. Using the description you also get a documented makefile/taskfile.
Now it`s time to get a coffee and install the first module:
- Install module “table”
task deploy-module-table
After a while you get:
Validating your module fragments...
Creating CloudFormationManagedUploadInfrastructure
CloudFormationManagedUploadInfrastructure stack was successfully created
Successfully submitted type. Waiting for registration with token 'a620b1d6-99f1-4fc1-973a-f6020338c7c7' to complete.
Registration complete.
{'ProgressStatus': 'COMPLETE', 'Description': 'Deployment is currently in DEPLOY_STAGE of status COMPLETED; ', 'TypeArn': 'arn:aws:cloudformation:eu-central-1:230287552993:type/module/tecracer-dynamodb-gotable-MODULE', 'TypeVersionArn': 'arn:aws:cloudformation:eu-central-1:230287552993:type/module/tecracer-dynamodb-gotable-MODULE/00000001', 'ResponseMetadata': {'RequestId': '414cfe50-f10a-41e1-8e8f-234a8e0940e9', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': '414cfe50-f10a-41e1-8e8f-234a8e0940e9', 'content-type': 'text/xml', 'content-length': '705', 'date': 'Thu, 10 Dec 2020 10:41:36 GMT'},
While sipping from your coffee, let me explain the structure of the infrastructure:
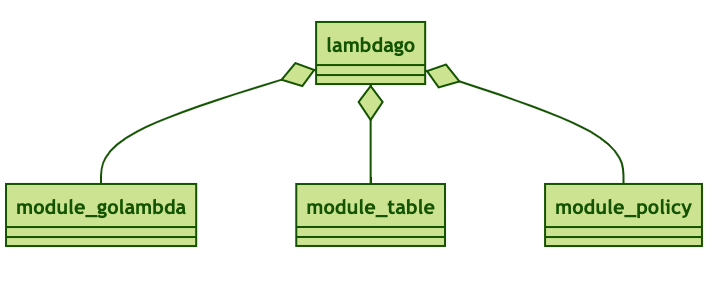
The main cloudformation template is called lambdago and is rather short:
Resources:
golambda:
Type: tecracer::lambda::golambda::MODULE
Properties:
DeploymentBucket: !Ref Bucket
DeploymentKey: !Ref Key
Table: !Ref uploadsTable
uploads:
Type: tecracer::dynamodb::gotable::MODULE
tablepolicy:
Type: tecracer::IAM::tablepolicy::MODULE
Properties:
tableParm: !GetAtt uploadsTable.Arn
functionrole: !Ref golambdaLambdaGoServiceRole
In the resource section you reference the modules like the table module:
uploads:
Type: tecracer::dynamodb::gotable::MODULE
What cfn-modules does, is to fetch the table module, which is defined in serverless-standard/cloudformation/table-module/fragments/table.json and expand it into the cloudformation.
So this modules (must be defined in json):
"Resources": {
"Table": {
"Type": "AWS::DynamoDB::Table",
"Properties": {
"KeySchema": [
{
"AttributeName": "itemID",
"KeyType": "HASH"
}
],
"AttributeDefinitions": [
{
"AttributeName": "itemID",
"AttributeType": "S"
}
],
"ProvisionedThroughput": {
"ReadCapacityUnits": 5,
"WriteCapacityUnits": 5
}
},
"UpdateReplacePolicy": "Delete",
"DeletionPolicy": "Delete"
}
}
is expanded in the resulting cloudformation template:
uploadsTable:
Type: AWS::DynamoDB::Table
DeletionPolicy: Delete
UpdateReplacePolicy: Delete
Metadata:
AWS::Cloudformation::Module:
TypeHierarchy: tecracer::dynamodb::gotable::MODULE
LogicalIdHierarchy: uploads
Properties:
AttributeDefinitions:
- AttributeType: S
AttributeName: itemID
ProvisionedThroughput:
WriteCapacityUnits: 5
ReadCapacityUnits: 5
KeySchema:
- KeyType: HASH
AttributeName: itemID
You see that the naming is just $modulename$resourcename.
uploadsTable:
...
Therefore you can directly reference resources in modules. As this is an easy way to access the resources of a module, from the view of clean programming, it would have been better to hide the module internals.
Also note, that inside a module an output may not contain an export.
- install module lambda
task deploy-module-lambda
Now we use the time to look at the deploy command:
cfn submit -v --set-default
submit ist the deploy command for the module. At the beginning of a module development you create a directory and execuite an cfn init inside that directory.
cfn init
Initializing new project
Do you want to develop a new resource(r) or a module(m)?.
>> m
What's the name of your module type?
(<Organization>::<Service>::<Name>::MODULE)
>> tecracer::lambda::golambda::MODULE
Directory /Users/silberkopf/Documents/projects/tecracer-github/tRick-benchmarks/serverless-standard/cloudformation/golambda-module/fragments Created
Initialized a new project in /Users/silberkopf/Documents/projects/tecracer-github/tRick-benchmarks/serverless-standard/cloudformation/golambda-module
After initialisation you edit your fragment (like fragments/golambda.json) in the fragments subdirectory.
Each time you submit a new version is created, but not set as default version. If you submit changes to your module, without adding --set-default as paramater to your submit command, the main cloudformation will continue to use the old default version.
- Install last module
task deploy-module-policy
We have installed three modules - time to look at the CloudFormation console where to find the stuff:
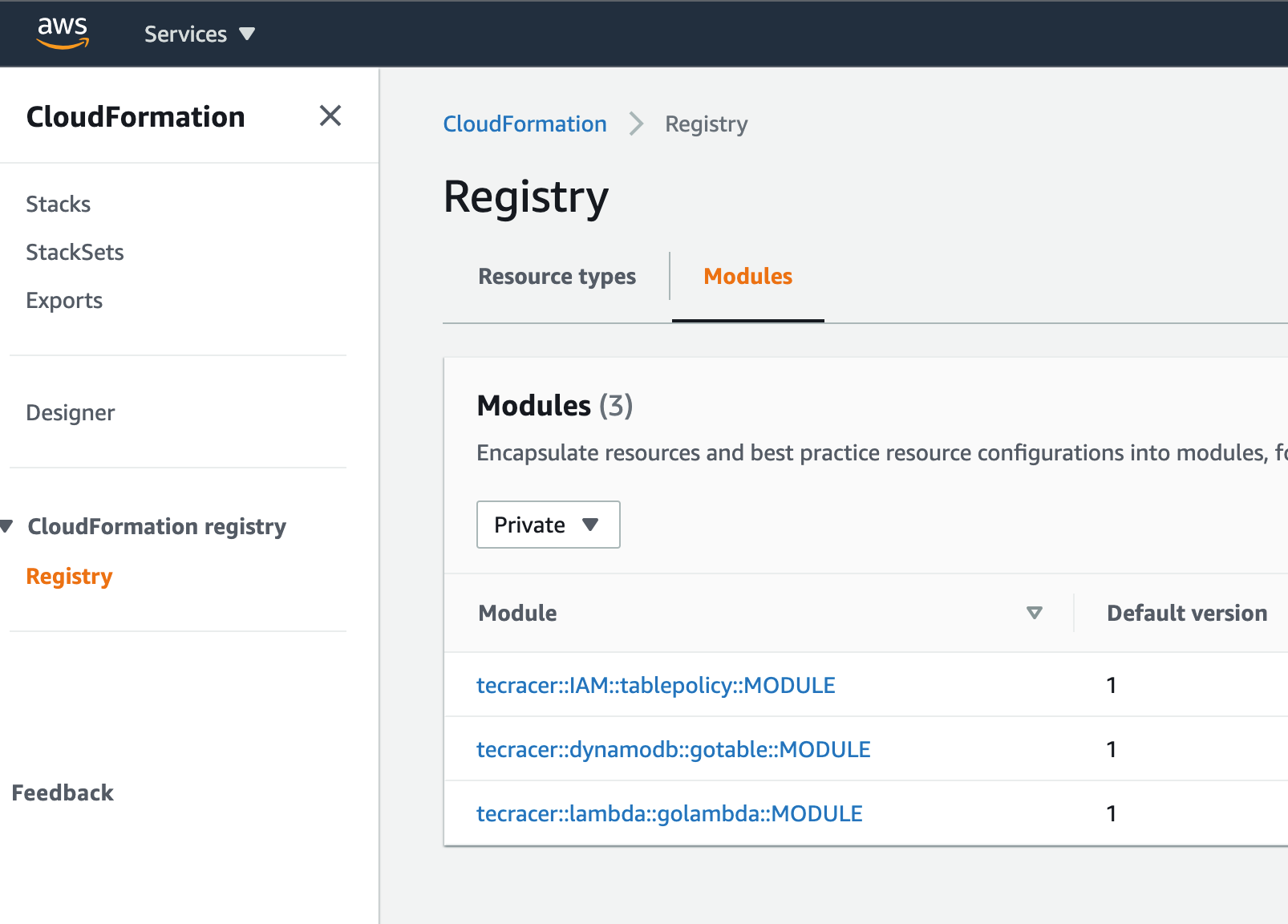
Now the modules can be used, so deploy the template itself.
To have a nice look at the tail of the event log, we use cfn-tail
- Install cfn-tail
npm install -g cfn-tail
Create the lambda function zip
CloudFormation has no native support for lambda function code. Therefore we need to create a bucket and upload the lambda code as zip.
The architecture for this serverless trick benchmark can be found on github:
- Change to function code directory
cd lambda/
- Build the function code bundled in a zip file
task build
- Create a deployment bucket
Create a bucket and put the bucket name in the two configuration files:
This is the configuration where the build process of the lambda code puts the artifact.
a) serverless-standard/cloudformation/lambda/Taskfile.yml
vars:
BUCKET: <bucketname here>
Example:
vars:
BUCKET: cloudformationmanageduploadinfra-accesslogsbucket-ups9jp5vg5w9
And this is the parameter for the CloudFormation template. This tells the lambda resource from which bucket it should fetch the code.
b) serverless-standard/cloudformation/parms.json
{
"ParameterKey": "Bucket",
"ParameterValue": "<bucketname here>"
},
example
{
"ParameterKey": "Bucket",
"ParameterValue": "cloudformationmanageduploadinfra-accesslogsbucket-ups9jp5vg5w9"
},
If you are doing this on clean account with cloud9, you can take one of the created “cloudformation management” buckets. For production you should create your own deployment bucket.
Then - still inside the lambda subdir - you deploy the function code to s3:
- Deploy lambda code
task s3deploy
The output is like:
task: Task "build" is up to date
task: aws s3 cp ./dist/main.zip s3://cloudformationmanageduploadinfra-accesslogsbucket-ups9jp5vg5w9/lambda-latest.zip --region eu-central-1
upload: dist/main.zip to s3://cloudformationmanageduploadinfra-accesslogsbucket-ups9jp5vg5w9/lambda-latest.zip
In the first line “Task “build” is up to date” you see the dependency to the build script.
sources:
- ./*.go
- main/*.go
generates:
- dist/main
In the taskfile the build task compares the timestamp of the source files *.go with the generated file main. Only if the source files are changed, a build is triggered.
Now the lambda code is uploaded to the s3 bucket. This is the prefered way to deploy function code. You could deploy it directly in the cloudformation, but you have size limits with that.
Developing lambda functions, you only need to provision the infrastructure once. If no parameter from lambda is changed, you can just upload the zip file to the s3 bucket. After that call the update function action:
aws lambda update-function-code --function-name {{.FN}} --zip-file fileb://dist/main.zip
like in the task “fastdeploy” in the Taskfile.yml file.
This is described in depth in this post: Lambda fast deploy
Deploy the stack
Now we have created all dependencies and can deploy the stack itself:
- Deploy stack
cd ..
task deploy-stack
This will take some time, because this (safely) uses deploy instead of create-stack. Lets look at the command:
aws cloudformation deploy --stack-name trick-cloudformation --template-file lambdago.yaml --capabilities CAPABILITY_AUTO_EXPAND CAPABILITY_IAM --parameter-overrides file://parms.json
| Parameter | meaning |
|---|---|
| cloudformation | service name |
| cloudformation deploy | advanced create/update stack with changesets |
| stack name | stack name |
| template file | the main template. Referencing syntax with create stack is different |
| capabilities CAPABILITY_AUTO_EXPAND | Because cfn modules expand the template file with the included modules, you need this |
| CAPABILITY_IAM | capability to create the Lambda role |
| parameter-overrides | The parameter file, in which the deployment bucket and zip package is referenced |
CloudFormation has two actions for deploying stacks.
With create-stack it will not create a changeset. Therefore this is faster. But when you update the stack, you have to call a different action called update-stack.
With deploy-stack you may call the same command for creation and for update.
Now you can call the lambda function in the console. Use S3-put as test json. You will get something like:
START RequestId: 84116a5f-e05f-4a14-8912-65aa65197952 Version: $LATEST
Response &{map[] <nil> <nil> {map[{}:AE6O0BJQKM24TS4I8OLCHVQ0F7VV4KQNSO5AEMVJF66Q9ASUAAJG {}:{{13829697702273486072 184406178 0xd91f00} {0 63743283878 <nil>} -252447992}]}}
END RequestId: 84116a5f-e05f-4a14-8912-65aa65197952
REPORT RequestId: 84116a5f-e05f-4a14-8912-65aa65197952 Duration: 133.59 ms Billed Duration: 134 ms Memory Size: 1024 MB Max Memory Used: 46 MB Init Duration: 80.09 ms
You notice the 1ms billing (Duration 133,59, billed 134 ms) - thats a new feature from reinvent 2020!
But the output from the response has to be changed.
Update Lambda code
After editing the golang code, with task fastdeploy the build and updating the function takes about 2 seconds.
time task fastdeploy
updating: main (deflated 65%)
task: aws lambda update-function-code --function-name trick-cloudformation-golambdaLambdaGo-120COE5RYL5BI --zip-file fileb://dist/main.zip
{
"FunctionName": "trick-cloudformation-golambdaLambdaGo-120COE5RYL5BI",
"FunctionArn": "arn:aws:lambda:eu-central-1:12345679812:function:trick-cloudformation-golambdaLambdaGo-120COE5RYL5BI",
"Runtime": "go1.x",
"Role": "arn:aws:iam::12345679812:role/trick-cloudformation-golambdaLambdaGoServiceRole-1WDF1184L2ASC",
"Handler": "main",
"CodeSize": 3589115,
"Description": "",
"Timeout": 3,
"MemorySize": 1024,
"LastModified": "2020-12-12T16:00:39.310+0000",
"CodeSha256": "lVaGYuCMzHITz6UFP7nlfF5yZQcEl6y9tNwDuP+zmb8=",
"Version": "$LATEST",
"Environment": {
"Variables": {
"TableName": "trick-cloudformation-uploadsTable-1Q78TXZLL9MEX"
}
},
"TracingConfig": {
"Mode": "PassThrough"
},
"RevisionId": "fadd3b1b-e912-4365-9b87-936d7b11c883",
"State": "Active",
"LastUpdateStatus": "Successful"
}
task fastdeploy 2,04s user 1,34s system 80% cpu 4,196 total
If we deploy the function code via the bucket with task fastlargedeploy it will take 100% more time, about 4 seconds.
time task fastlargedeploy
updating: main (deflated 65%)
task: aws s3 cp ./dist/main.zip s3://cloudformationmanageduploadinfra-accesslogsbucket-ups9jp5vg5w9/lambda-latest.zip --region eu-central-1
(deflated 65%)ompleted 256.0 KiB/3.4 MiB (1.0 MiB/s) with 1 file(s) remaining
upload: dist/main.zip to s3://cloudformationmanageduploadinfra-accesslogsbucket-ups9jp5vg5w9/lambda-latest.zip
task: aws lambda update-function-code --function-name trick-cloudformation-golambdaLambdaGo-120COE5RYL5BI --s3-bucket cloudformationmanageduploadinfra-accesslogsbucket-ups9jp5vg5w9 --s3-key lambda-latest.zip
{
"FunctionName": "trick-cloudformation-golambdaLambdaGo-120COE5RYL5BI",
"FunctionArn": "arn:aws:lambda:eu-central-1:230287552993:function:trick-cloudformation-golambdaLambdaGo-120COE5RYL5BI",
"Runtime": "go1.x",
"Role": "arn:aws:iam::230287552993:role/trick-cloudformation-golambdaLambdaGoServiceRole-1WDF1184L2ASC",
"Handler": "main",
"CodeSize": 3589115,
"Description": "",
"Timeout": 3,
"MemorySize": 1024,
"LastModified": "2020-12-12T16:06:44.690+0000",
"CodeSha256": "x9WKOoGqGIEbsOVgijtyTPilaEuXy65UUJ4ZHI2dcR4=",
"Version": "$LATEST",
"Environment": {
"Variables": {
"TableName": "trick-cloudformation-uploadsTable-1Q78TXZLL9MEX"
}
},
"TracingConfig": {
"Mode": "PassThrough"
},
"RevisionId": "08ab7225-3eab-4f25-876e-83787bb60d25",
"State": "Active",
"LastUpdateStatus": "Successful"
}
task fastlargedeploy 3,83s user 2,59s system 121% cpu 5,290 total
The different lambda deployment Options
The difference between deploying directly in the api call and via s3 is the upload limit.
In the limit page you see:
| Limit | Method |
|---|---|
| 3 MB | console editor |
| 50 MB | zipped, direct upload |
| 250 MB | unzipped, including layers |
| 10 GB | Container image code package size |
That means: Until you lambda upload zip has reached 50 MB, you may safely use the direct upload method.
So when you compare the different frameworks for convience and speed of the upload of function code: You can upload up to 50 MB function very fast directly with a few lines of a makefile.
Or with 20 lines of a lambda function which uses s3 put events to upload another lambda function:
console.log('Loading function');
var AWS = require('aws-sdk');
var lambda = new AWS.Lambda();
exports.handler = function(event, context) {
key = event.Records[0].s3.object.key
bucket = event.Records[0].s3.bucket.name
version = event.Records[0].s3.object.versionId
if (bucket == "YOUR_BUCKET_NAME" && key == "YOUR_CODE.zip" && version) {
var functionName = "YOUR_FUNCTION_NAME";
console.log("uploaded to lambda function: " + functionName);
var params = {
FunctionName: functionName,
S3Key: key,
S3Bucket: bucket,
S3ObjectVersion: version
};
lambda.updateFunctionCode(params, function(err, data) {
if (err) {
console.log(err, err.stack);
This methods is from the “stone age”, means 2015:New Deployment Options for AWS Lambda .
Lambda update ok
I have changed the return value to a single message, the lambda is updated. A call gives:
START RequestId: e7d6e91a-b32b-4276-85a5-cdc50776bdcf Version: $LATEST
Write ok
END RequestId: e7d6e91a-b32b-4276-85a5-cdc50776bdcf
REPORT RequestId: e7d6e91a-b32b-4276-85a5-cdc50776bdcf Duration: 126.67 ms Billed Duration: 127 ms Memory Size: 1024 MB Max Memory Used: 45 MB Init Duration: 85.69 ms
Summary
On the plus side
With modules you may create simple templates with large functionality. I expect that there will be a growing number of modules examples.
See the AWS cfn modules on github
Also you can enforce the use of a certain parameters set. In this example I have used golang as a language for Lambda. If all Lambda functions are using the same language, you don’t need to set it in each function, you may set it in the module. If a new version of a language like node should be used, you could update the version for all functions only in the cfn module. But you would have to test each function with the new version nevertheless.
Setting the memory default for all functions - just define it in the module.
If you use “create/update” and lambda fastdeploy you are faster than the cdk. Serverless also uses the direct api deployment, so you will not be faster than serverless.
If you have to use additional resources, the cdk has the easyiest way to add new resources. With serverless and cfn modules you have to declare them explicitly via cloudformation.
I think the main advantage is the simplicity of the resulting template:
golambda:
Type: tecracer::lambda::golambda::MODULE
Properties:
DeploymentBucket: !Ref Bucket
DeploymentKey: !Ref Key
Table: !Ref uploadsTable
And compared to cdk, cloudformation is more stable in the syntax of the resources.
The downsides
There are also some disadvantages.
Local development Modules
What is missing is a module function on the development environment, when you write the template.
In January 2017 i used a template language for my CloudFormation projects. The original post was in german, this is the deepl translated version: Velocity for complex CloudFormation templates
I used velocity because this was the same templating language API gateway is using API Gateway Templates.
AWS now is using another templating language Jinja for AWS Proton.
Proton is another way to create CloudFormation “modules” for your team. And with proton you may use templating enhancments - just like with veliocity - variables, include blocks, loops and more.
The example of the lambda function from proton aws proton samples
Looks like this:
{% if service_instance.code_uri|length %}
ListFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: "{{service_instance.code_uri}}"
Handler: "{{service_instance.resource_handler}}.list_{{service_instance.resource_name}}"
Runtime: "{{service_instance.lambda_runtime}}"
The problem I see ist if you use a templating language you are halfway to a “real” programming language without the power and advantages of a real language. Why are we doing the effort of creating usable modules in cfn-modules and (with a much faster pace) in cdk?
In the end cdk, cloudformation modules, terraform and serverless are generating declarative code, see The declarative vs imperative Infrastructure as Code discussion is flawed.
Cross account modules
The next thing would be to efficiently distribute modules across accounts. If I create templates in the dev environment, they should run on the production environment as well. If I develop modules for the whole company, they must be distributed.
Sooo…
Is CloudFormation modules suitable for serverless development?
If you decided to use pure CloudFormation and not the CDK, i think that there are some good reasons you should use CloudFormation modules. You get a real clean main template. Combine this with nested templates and you have enough possibilities to break down a larger problem into smaller chunks.
You should also consider the option generating cfn with cdk and using the generated code. The generated code is not so clean as the manually written code. But the availability of ready-to-use components within the cdk (call it constructs or modules) is way ahead of modules.
So you have different choices for you serverless projects - and that is a good thing!
Thank you
I hope you enjoyed reading this article. For feedback, questions and anything else you might want to share, feel free to reach out to me on twitter (@megaproaktiv) or any of the other networks listed in the cards below.
Maybe you also want to take a look at our youtube channel: tecRacer@youtube.
You find the code in our tecRacer tRick on github in the subdirectory