Erste Einblicke in CloudWatch Logs Insights
This content is more than 4 years old and the cloud moves fast so some information may be slightly out of date.
Mal unter uns - in der Analyse der Logdateien hat CloudWatch logs bisher nicht gerade geglänzt. Das Feld wurde eher anderen Kandidaten überlassen. Jetzt hat man die Analysefähigkeit aufpoliert. Daher ist es Zeit sich das genauer anzuschauen. _TL;DR : Nicht schlecht gemacht, einen Blick wert! _ Verschiedene Auswertungen von vordefinierten und eigenen Feldern, kombiniert mit einer einfache Visualisierung können schon viele Anwendungsfälle erschlagen.
Testfunktion erzeugt Log Einträge
Ich nehme zum Test eine Lambda Function “pandocs3converter”, die auf einem S3 Bucket Markdown Texte in Docx umwandelt. Dabei werden Logeinträge durch Hochladen von Dateien erzeugt. Für Lambda Funktionen werden durch Inisght standardmäßig die Felder @timestamp,@logStream,@message,@requestId,@duration, ``@billedDuration,@type,@maxMemoryUsed,@memorySize bereitgestellt. Als erstes kann ich mir also mit
fields @timestamp, @type, @message | head 30
eine einfache Auswertung anzeigen lassen. Insight hilft mir bereits bei der Auswahl der Log Group mit Autocompletion: 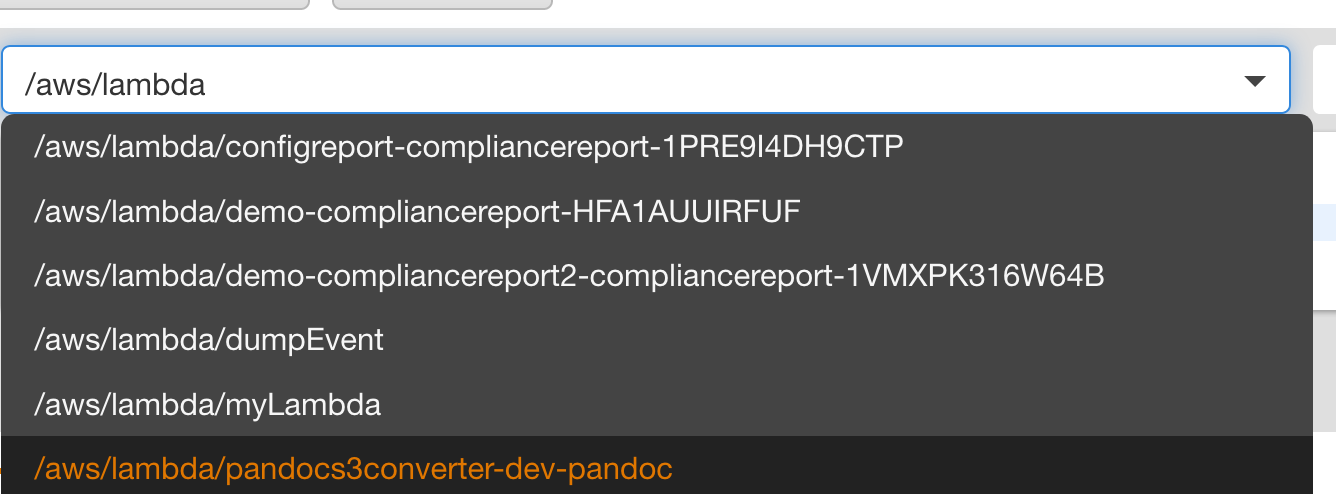
Eine einfache query
Rechts gibt es ein “commands” Fenster, aus dem ich jetzt “fields” auswähle. Die Felder erste ich durch “@timestamp, @type, @message | head 30 “. Damit bekomme ich die ersten 30 Zeilen.
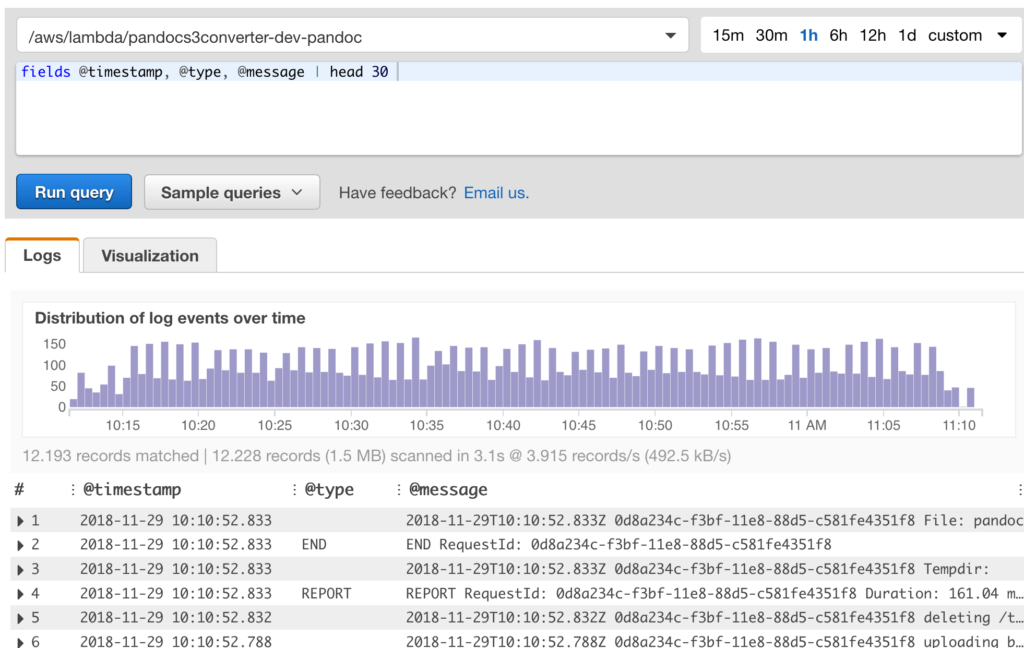
Die query wird ausgeführt und ich sehe die Ergebnisse. Hier sehen wir auch schon, wie das Feld “@type” gefüllt wird oder auch nicht.
Grafische Auswertung
Jetzt habe ich auch Möglichkeiten mit verschiedenen Funktionen Visualisierungen darzustellen. Die Informationen über die Ausführungszeit stehen bei Lambda im “REPORT” Satz. Daher kann ich mit
filter @type = "REPORT"
| stats avg(@duration), max(@duration), min(@duration) by bin(1min)
Eine Auswertung über Mittelwert, Maxima- und Minimalwert der Ausführungsdauer bekommen:

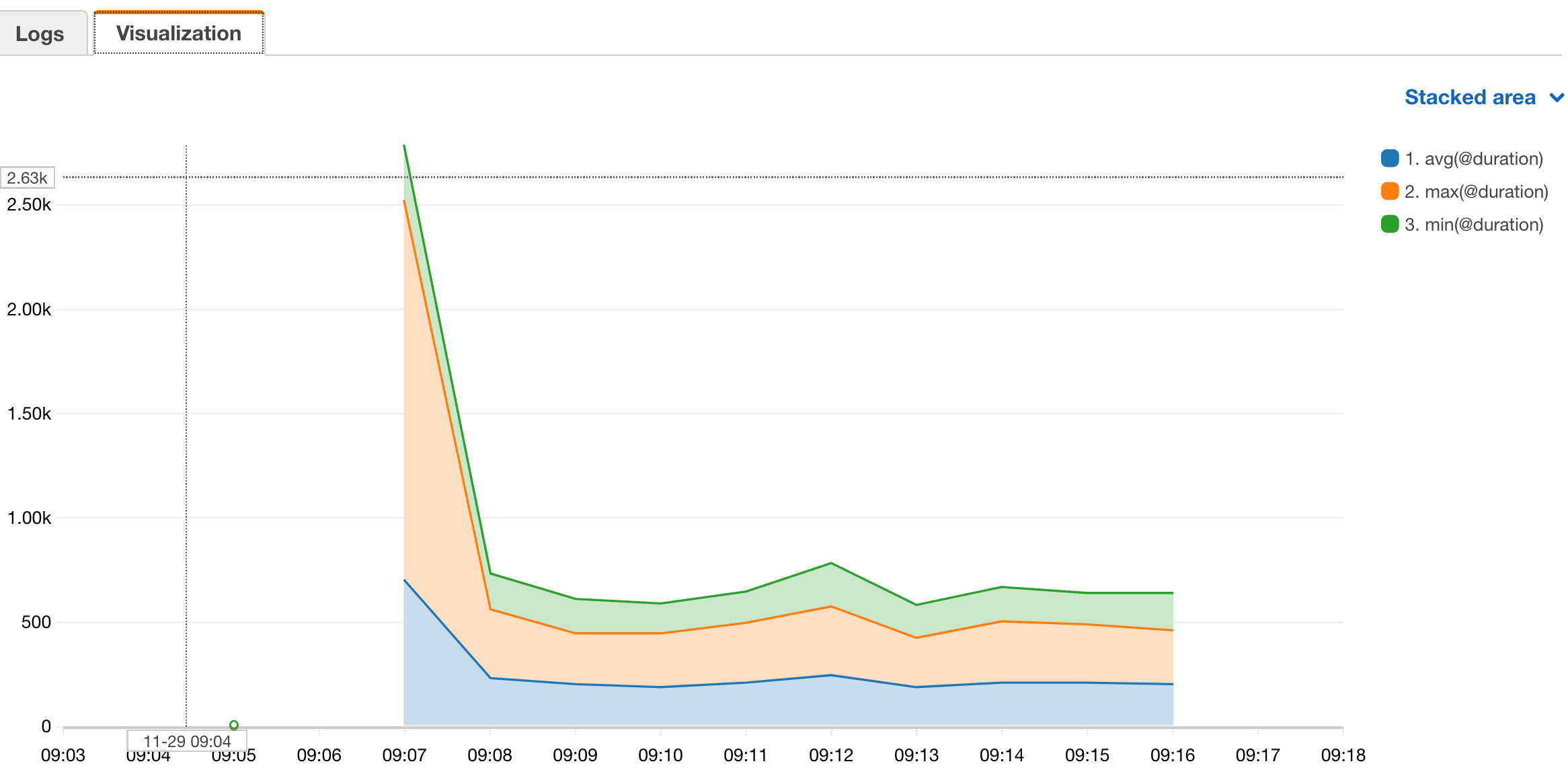
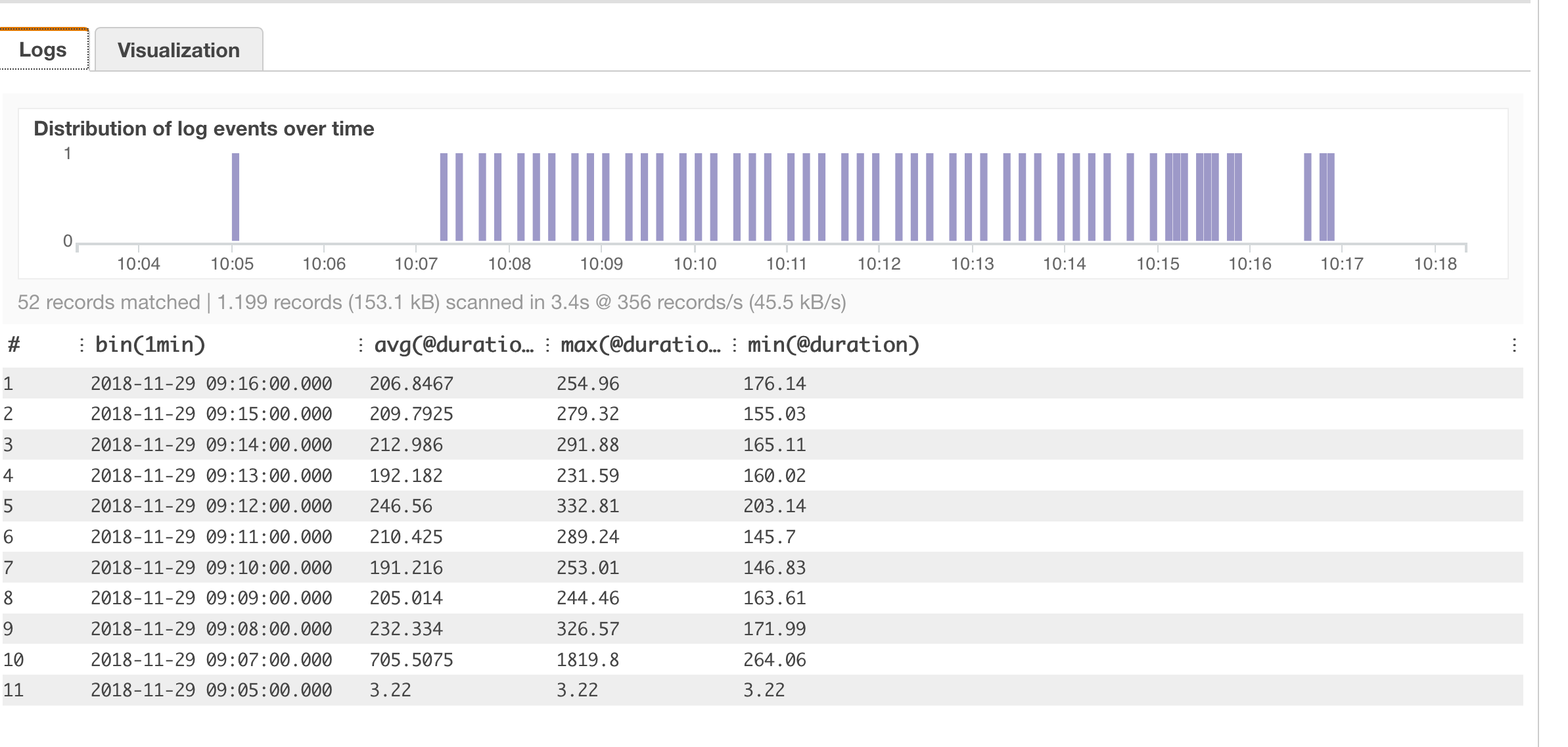
Man sieht in der Grafik schön den ersten Kaltstart der Lambda Funktion.
Auswerten eigener Felder
Die lambda verarbeitet Objekte, die auf einen S3 Bucket hochgeladen werden. Ich will jetzt wissen, welche Objekte verarbeitet wurden. Das könnte ich dann später mit Zählen der Ereignisse (count) usw. erweitern. Dazu kann ich das “parse” Kommando verwenden.
Im Log steht:
2018-11-29T09:08:04.974Z 47c76fee-f3b6-11e8-9d80-937cf190f299 Key: Training/M03-Tools\\\_CROW\\\_STORIES.md
Ich kann mit Logs Insights “parse” diese Information in ein Feld, hier “@Key” umwandeln. Interessant ist, dass man dieses Feld z.B. im Filter gleich weiter verwenden kann. Die komplette Zeile im Log ist in dem Feld @message hinterlegt.
Dort kann ich mit dem Pattern “Key: *” nach dem Feld suchen.
Im Filter filtere ich mit einer Regular Expression Felder heraus, die auch einen Inhalt haben, also “.” - ein Zeichen “*” mehrfach.
parse @message "Key: *" as @Key
| fields @timestamp, @File, @message
| filter @Key like /.*/
| sort @timestamp desc
| head 30
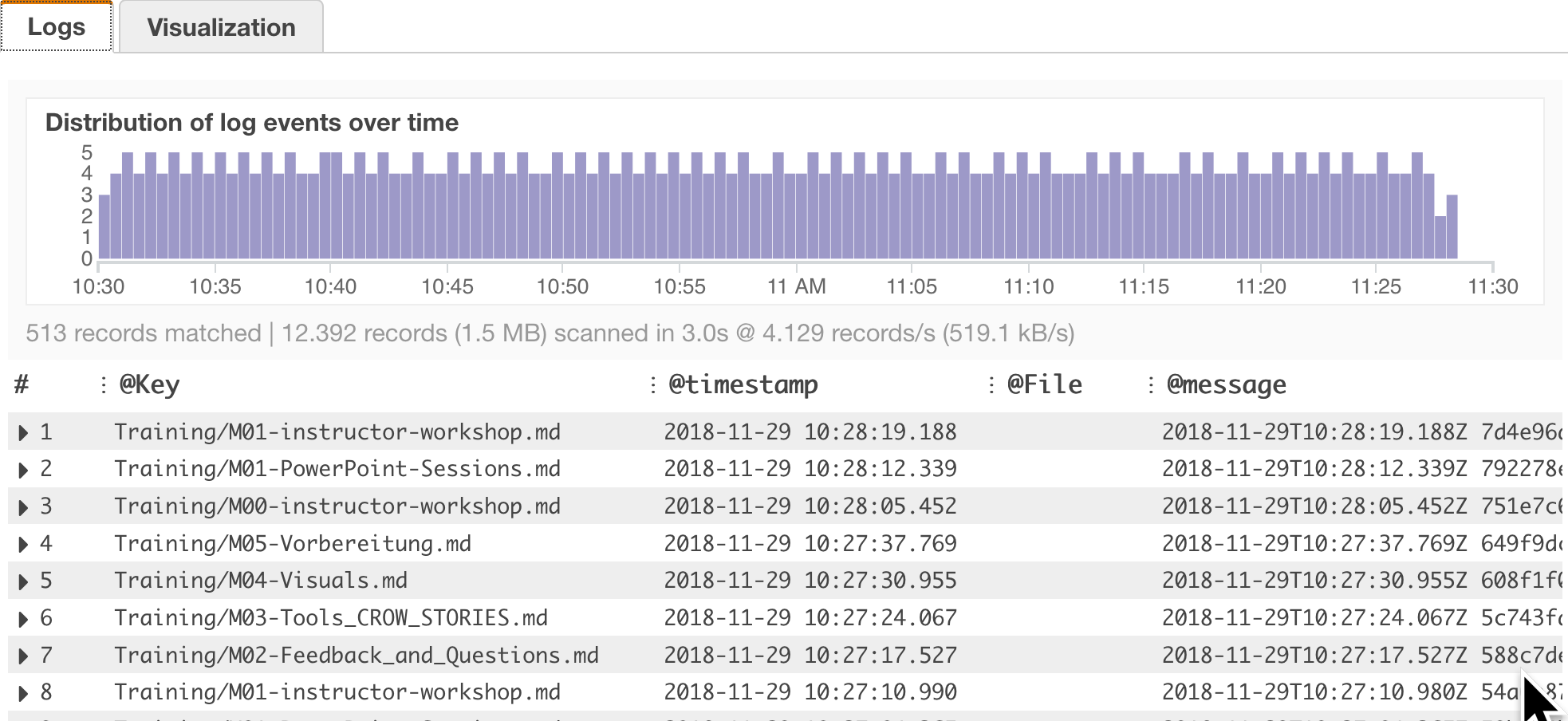
Das Ergebnis mit eigenen Felder.
Man kann also auf Anhieb viel mehr machen als mit den normalen Filterfunktionen von CloudWatch Logs und spart sich so eventuell eine zusätzliche Architektur und ein zusätzliche Applikation, wie z.B. beim Serverless Hero Yan Cui hervorragend beschrieben:
/centralised-logging-for-aws-lambda-revised-2018.
Und jetzt viel Spaß beim Ausprobieren!
Photo (edited) by Paweł Czerwiński on Unsplash